
With the B.Tech AKTU Quantum Book, you can delve into the world of Machine Learning Techniques. Learn how to master this groundbreaking field by accessing critical notes, repeated questions, and useful insights. Unit-3 Decision Tree Learning
Dudes 🤔.. You want more useful details regarding this subject. Please keep in mind this as well. Important Questions For Machine Learning Techniques: *Quantum *B.tech-Syllabus *Circulars *B.tech AKTU RESULT * Btech 3rd Year * Aktu Solved Question Paper
Q1. Describe the basic terminology used in decision tree.
Ans. Basic terminology used in decision trees are:
- 1. Root node: The complete population or sample is represented, and this is then separated into two or more homogeneous sets.
- 2. Splitting: It is a process of dividing a node into two or more sub-nodes.
- 3. Decision node: When a sub-node splits into further sub-nodes, then it is called decision node.
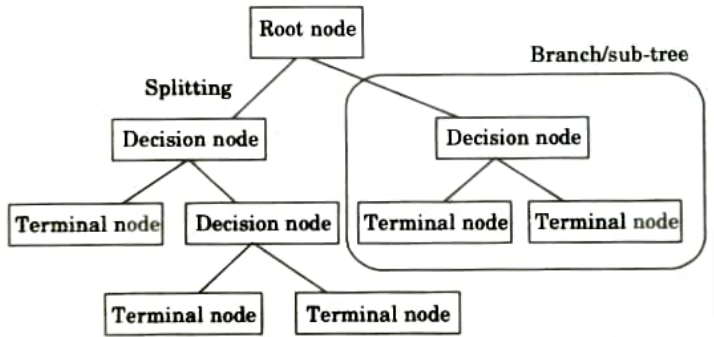
- 4. Leaf/Terminal node: Nodes that do not split is called leaf or terminal node.
- 5. Pruning: Pruning is the process of removing sub-nodes from a decision node. The dividing process is in opposition to this one.
- 6. Branch/sub-tree: A sub section of entire tree is called branch or sub tree.
- 7. Parent and child node: The parent node of sub-nodes is a node that has been divided into sub-nodes, whereas sub-nodes are the parent node’s offspring.
Q2. Explain various decision tree learning algorithms.
Ans. Various decision tree learning algorithms are:
1. D3 (Iterative Dichotomiser 3):
- i. A decision tree can be created using the D3 technique using a dataset.
- ii. To build a decision tree, ID3 does a top-down, greedy search across the provided sets, testing each attribute at each tree node to determine which attribute is most effective for categorizing a specific e.
- iii. As a result, the test attribute for the present node can be chosen as the attribute with the largest information gain.
- iv. This algorithm favours smaller decision trees over larger ones. As it does not build the smallest tree, it is a heuristic algorithm.
- v. Only categorical attributes are accepted by ID3 when creating a decision tree model. When there is noise and when ID3 is used serially, accurate results are not produced.
- vi. Consequently, data is preprocessed before a decision tree is built.
- vii. Information gain is determined for each and every attribute used in the construction of a decision tree, and the attribute with the highest information gain is indicated by arcs. the root node appears. The remaining potential values are indicated.
- viii. All potential result examples are analyzed to see if they all fall under the same class or not. When referring to instances of the same class, the class is identified by a single name; otherwise, instances are categorized according to the splitting attribute.
2 C4.5:
- i. The algorithm C4.5 is employed to create a decision tree. It is an improvement to the ID3 algorithm.
- ii. C4.5 is referred to as a statistical classifier since it creates decision trees that may be used for categorization.
- iii. It handles both continuous and discrete attributes, as well as missing values and pruning trees after construction, making it superior to the ID3 method.
- iv. C5.0 is the commercial replacement for C4.5 since it is quicker, uses less memory, and can create smaller decision trees.
- v. Version C4.5 executes a tree pruning operation by default. Smaller trees are created as a result, along with straightforward rules and more logical interpretations.
3. CART (Classification And Regression Trees):
- i. CART algorithm builds both classification and regression trees.
- ii. The classification tree is constructed by CART through binary splitting of the attribute.
- iii. Gini Index is used for selecting the splitting attribute.
- iv. The CART is also used for regression analysis with the help of regression tree.
- v. The regression feature of CART can be used in forecasting a dependent variable given a set of predictor variable over a given period of time.
- vi. CART has an average speed of processing and supports both continuous and nominal attribute data.
Q3. Explain inductive bias with inductive system.
Ans. Inductive bias:
- 1. The limitations imposed by the learning method’s presumptions are referred to as inductive bias.
- 2. Assume, for instance, that a conjunction of a group of eight notions can be used to describe a solution to the problem of road safety.
- 3. More intricate phrases that cannot be stated as conjunctions are not permitted by this.
- 4. Because of this inductive bias, we are unable to study some potential solutions because they are outside the version space that we have looked at.
- 5. Every potential hypothesis that may be articulated would need to be present in the version space in order to have an impartial learner.
- 6. The whole collection of training data could never be more general than the answer the learner came up with.
- 7. In other words, it would be able to categorize information that it had already seen (much like a rote learner could), but it would be unable to generalize to categorize information that it had never seen before.
- 8. The candidate elimination algorithm’s inductive bias prevents it from classifying fresh data unless all of the hypotheses in its version space assign the same classification to it.
- 9. As a result, the learning approach is constrained by the inductive bias.
Inductive system:

Ans. Issues related to the applications of decision trees are:
1. Missing data:
- a. When values have gone unrecorded, or they might be too expensive to obtain.
- b. Two problems arise:
- i. To classify an object that is missing from the test attributes.
- ii. To modify the information gain formula when examples have unknown values for the attribute.
2. Multi-valued attributes:
- a. The information gain measure provides an inaccurate representation of an attribute’s usefulness when it has a wide range of possible values.
- b. In the worst scenario, we might employ an attribute with a unique value for each sample.
- c. The information gain measure would then have its highest value for this feature, even though the attribute might be unimportant or meaningless, since each group of samples would then be a singleton with a distinct classification.
- d. Using the gain ratio is one option.
3. Continuous and integer valued input attributes:
- a. There are an endless number of possible options for height and weight.
- b. Decision tree learning algorithms discover the split point that provides the best information gain rather than creating an endless number of branches.
- c. Finding suitable Split points can be done efficiently using dynamic programming techniques, but this is still the most expensive step in practical decision tree learning applications.
4. Continuous-valued output attributes:
- a. A regression tree is required when attempting to predict a numerical value, such as the cost of an artwork, as opposed to discrete classifications.
- b. Rather than having a single value at each leaf, such a tree has a linear function of a subset of numerical properties.
- c. The learning algorithm must determine when to stop splitting and start using the remaining attributes in linear regression.
Q5. What are the advantages and disadvantages of K-nearest neighbour algorithm ?
Ans. Advantages of KNN algorithm:
- 1. No training period:
- a. KNN is referred to as a lazy learner (Instance-based learning).
- b. Throughout the training phase, it does not learn anything. The training data are not used to derive any discriminative function.
- c. In other words, it doesn’t require any training. Only when making real-time predictions does it draw on the training dataset it has stored.
- d. As a result, the KNN method runs significantly more quickly than other algorithms, such as SVM, Linear Regression, etc., that call for training.
- 2. As the KNN algorithm doesn’t need to be trained before producing predictions, new data can be supplied without disrupting the algorithm’s accuracy.
- 3. KNN is quite simple to use. KNN implementation just needs two parameters: the value of K and the distance function (for example, Euclidean).
Disadvantages of KNN:
- 1. Does not work well with large dataset: In large datasets, the algorithm’s speed suffers due to the high cost of computing the distance between each new point and each current point.
- 2. Does not work well with high dimensions: The KNN technique does not perform well with high dimensional data because it becomes challenging for the algorithm to calculate the distance in each dimension when there are many dimensions.
- 3. Need feature scaling: Before we apply the KNN method to any dataset, we must do feature scaling (standardization and normalization). In the absence of this, KINN may produce inaccurate forecasts.
- 4. Sensitive to noisy data, missing values and outliers: KNN is sensitive to dataset noise. Outliers must be eliminated, and missing values must be manually represented.
Q6. What are the benefits of CBL as a lazy problem solving method ?
Ans. The benefits of CBL as a lazy Problem solving method are:
- 1. Ease of knowledge elicitation:
- a. Instead of hard to extract rules, lazy methods can use readily available case or problem instances.
- b. As a result, case gathering and structure take the place of traditional knowledge engineering.
- 2. Absence of problem-solving bias:
- a. Cases can be utilized for many different types of problem-solving since they are recorded in a raw format.
- b. This contrasts with eager procedures, which are limited to serving the original intent for which they were created.
- 3. Incremental learning:
- a. The ACBL system can be implemented with a small number of solved cases serving as the case basis.
- b. More cases will be added to the case base, enhancing the system’s capacity for problem-solving.
- c. In addition to expanding the case database, it is also possible to build new indexes and cluster types or modify those that already exist.
- d. In contrast, anytime informatics extraction (knowledge generalization) is carried out, a specific training period is needed.
- e. As a result, it is possible to adapt dynamically online to a flexible environment.
- 4. Suitability for complex and not-fully formalized solution spaces:
- a. CBL systems can be applied to a problem domain with an incomplete model; implementation requires both the identification of pertinent case features and the provision of appropriate cases, possibly from a partial case base.
- b. Lazy techniques, which replace the supplied data with abstractions acquired through generalization, are more suitable for complex solution spaces than eager approaches.
- 5. Suitability for sequential problem solving:
- a. The preservation of history in the form of a sequence of states or operations is beneficial for sequential activities, such as the reinforcement learning issues mentioned above.
- b. Such a storage is facilitated by lazy approaches.
- 6. Ease of explanation:
- a. The similarity of the current issue to the retrieved example can be used to justify the outcomes of a CBL system.
- b. CBL are simple to link to earlier incidents, making system failures easier to examine.
- 7. Ease of maintenance: This is especially true given that CBL systems can easily adjust to numerous changes in the issue domain and the pertinent environment through simple acquisition.

Machine Learning Techniques Btech Quantum PDF, Syllabus, Important Questions
| Label | Link |
|---|---|
| Subject Syllabus | Syllabus |
| Short Questions | Short-question |
| Question paper – 2021-22 | 2021-22 |
Machine Learning Techniques Quantum PDF | AKTU Quantum PDF:
| Quantum Series | Links |
| Quantum -2022-23 | 2022-23 |
AKTU Important Links | Btech Syllabus
| Link Name | Links |
|---|---|
| Btech AKTU Circulars | Links |
| Btech AKTU Syllabus | Links |
| Btech AKTU Student Dashboard | Student Dashboard |
| AKTU RESULT (One VIew) | Student Result |