
Software Testing: The previous year’s AKTU question paper with answers contains a complete set of exam-oriented questions and extensive solutions that help B.Tech students efficiently prepare for software testing tests.
Dudes 🤔.. You want more useful details regarding this subject. Please keep in mind this as well. Important Questions For Software Testing: *Quantum *B.tech-Syllabus *Circulars *B.tech AKTU RESULT * Btech 4th Year
Section A: Short Repeated Questions Software Testing
a. What is the difference between alpha testing and beta testing ?
Ans.
| S. No. | Alpha testing | Beta testing |
| 1. | Alpha testing is performed at the developer’s side. | Beta testing is performed at the end-user side of the product. |
| 2. | Alpha testing involves both the white box and black box testing. | Beta testing commonly uses black box testing. |
b. What is the need of software validation after a change ?
Ans. Because software is so complex, a minor local change can have a significant global system impact. When any changes are made to the software, the validation status must be re-established. When changing software, a validation analysis should be performed not only to validate the individual change, but also to determine the extent and impact of that change on the entire software system. Based on this analysis, the software developer should then perform an appropriate level of software regression testing to demonstrate that the system’s unchanged but vulnerable portions have not been adversely affected. Design controls and appropriate regression testing provide assurance that the software has been validated following a software change.
c. What is software testing ?
Ans. The goal of software testing is to find all flaws in a programme. Testing a programme entails feeding it a set of test inputs and watching to see if it behaves as expected. It is an important part of software quality assurance because it represents the final review of specification, design, and coding.
d. What are drivers and stubs ?
Ans. Driver :
The non-local data structures accessed by the module under test should be contained in a driver module. It should also include code for calling the various functions of the module under test with appropriate parameter values for testing.
Stub :
A stub procedure is a dummy procedure with the same Input/Output parameters as the given procedure but much simpler behaviour. A stub procedure, for example, may produce the expected behaviour by utilising a simple table look up mechanism.
e. What is the difference between testing techniques and testing tools ?
Ans. Testing techniques: Is a process for ensuring that some aspects of the application system or unit functions properly. There may be few techniques but many tools.
Testing tools: Is a vehicle for performing a test process. The tool is a resource to the tester, but itself is insufficient to conduct testing.
f. What is the difference between QA and testing?
Ans. Quality assurance: A set of activities designed to ensure that the development and/or maintenance processes are sufficient to ensure that a system meets its objectives.
Testing: The process of executing a system with the intent of finding defects.
g. How can you do black box testing of a database ?
Ans.
- 1. Black box testing entails verifying database integration to ensure functionality.
- 2. The test cases are straightforward and are used to validate incoming and outgoing data from the function.
- 3. To test the database’s functionality, various techniques such as cause-effect graphing, equivalence partitioning, and boundary-value analysis are used.
h. What is website testing?
Ans.
- 1. Web testing is the term used to describe software testing that focuses on web applications.
- 2. Web application testing, a software testing technique used solely to test web-hosted applications, in which the application interfaces and other functionalities are tested.
- 3. Before going into production, web-based applications are thoroughly tested. This stage of web testing identifies potential bugs in the system.
i. Write the tools for test data generation.
Ans.
- 1. One of the most important but time-consuming tasks is testing a data-aware application.
- 2. It is critical to test your application against “real” data.
- 3. A generator is required to populate your database with test data. Based on the column characteristics and/or what the user defines, the generators will generate realistic data for you.
j. What is the difference between software testing and debugging?
Ans.
| S. No. | Testing | Debugging |
| 1. | Testing always begins with known conditions, employs predefined methods, and yields predictable results. | Debugging begins with potentially unknown initial conditions and cannot be predicted except statistically. |
| 2. | Testing can and should definitely be planned, designed, and scheduled. | The procedures for, and period of, debugging cannot be so constrained. |
| 3. | It proves a programmers failure. | It is the programmer’s vindication. |
Section B : Aktu Long Solved Questions in Software Testing
a. How object oriented testing is different from procedural testing ?
Ans.
| Test method | Procedural software | Object-oriented software |
| Unit testing | Test individual, functionally cohesive operations. | Unit testing is really integration testing, test logically related operations and data. |
| Integration testing | Test an integrated set of units (operations and common global data). | Unit testing is a feature of object-oriented programming. There will be no more bugs relating to common global data (though could have errors associated with global object and classes). |
| Boundary value testing | Used on units or integrated units and systems. | Of limited value if using strongly typed object oriented languages and proper data abstraction is used to restrict the values of attributes. |
| Basis path testing | Generally performed on units. | Object operations are restricted. Exception handling and concurrency issues must be addressed (if applicable). The need for this is reduced as the object’s complexity decreases. |
| Equivalence and black box testing | Used on units integrated units and systems. | Emphasized for object-oriented : objects are black boxes, equivalence classes are messages. |
b. How do you measure software quality? Discuss correctness versus reliability pertaining to programs.
Ans. We have to consider following list of parameter or quality factors to measure software quality :
- 1. Correctness: Conformance to the specifications and user requirements.
- 2. Reliability: Performing expected functions with required precision.
- 3. Efficiency: Amount of resources required to execute required function.
- 4. Integrity: Security features or security controls implemented in software.
- 5. Usability: Effort required to understand, learn and operate the software.
- 6. Maintainability: Effort required to maintain the software.
- 7. Testability: Effort required to test the software.
- 8. Flexibility: Effort required to make changes to the software.
- 9. Portability: Effort required to port software from one to other platform or to configuration.
- 10. Re-usability: Extent to which program can be used in the other programs, which are performing same functions.
- 11. Interoperability: Effort required to couple systems with one another.
Correctness vs Reliability :
- 1. The correctness of the software will be established through requirement specifications and programme text to demonstrate that it is behaving as expected.
- 2. Reliability is the probability of a program’s successful execution on randomly selected elements from its input domain.
- 3. While programme correctness is desirable, it is almost never the goal of testing.
- 4. To establish correctness through testing, a programme must be tested on all elements in the input domain. In most cases encountered in practise, this is impossible to achieve.
- 5. Thus, programme correctness is established through mathematical proofs.
- 6. While correctness seeks to establish that the programme is error-free, testing seeks to identify any errors.
- 7. Thus, completeness of testing does not necessarily demonstrate that a program is error free.
c. Explain the various data flow testing criteria.
Ans.
- 1. Data flow testing is a technique used to detect improper use of data in a program.
- 2. By looking data usage, risky areas of code can be found and more test cases can be applied.
- 3. To test data flow, we devise control flow graph.
- 4. A data flow graph (DFG) is a graph which represents data dependencies between a numbers of operations.
- 5. In control flow testing, we find various paths of a program and design test case to execute those paths.
- 6. We may like to execute every statement of program at least once before the completion of testing.
- 7. Consider a program :
#include< stdio.h>
void main()
{
int a, b, c;
a = b + c;
printf(“%d”, a);
}
- 8. What will be the output ? The value of ‘a’ may be previously stored in the memory location assigned to variable ‘a’ or garbage value.
- 9. If we execute the program, we may get an unexpected value.
- 10. The mistake is in the usages of this variable without first assigning a value to it.
- 11. Data flow testing may help us to minimize such mistakes.
- 12. It has nothing to do with data flow diagram.
- 13. It is based on variables, their usages and their definitions in the program.
- 14. The main point of concern are :
- a. Statements where variable receive values (definitions).
- b. Statements where these values are used (referenced).
d. How reusability features can be exploited by object-oriented testing approach ?
Ans.
- 1. Reusability means being able to deal with the pressures of producing larger and more functional systems in a shorter development cycle.
- 2. Because the same code can be developed once and used in multiple applications, reusability allows developers to be more efficient.
- 3. Second, by reusing previously developed and tested components, reliability can be increased.
- 4. The development of new code incurs additional costs in terms of time and money for testing, validation, and verification. A large portion of these costs can be avoided by using “off-the-shelf” components.
- 5. Software reuse is not an exclusive goal of object-oriented programming. While libraries of procedures proved useful, procedures were too primitive a unit to encourage extensive reuse in practise.
- 6. Objects and classes are more sophisticated mechanisms for achieving software reuse because they bind together all aspects of an entire abstraction more completely.
- As a result, the abstraction can be more easily transferred across applications. Any type of generalisation can contribute to reuse.
- 8. When a class in an inheritance hierarchy serves as a generalised base class from which a new class is derived through specialisation, it can be reused directly.
- 9. Templates can be reused by supplying different parameters for the template arguments. Design patterns allow design experience and success to be reused across designers.
e. Explain cyclomatic complexity, its properties and meaning in tabular form.
Ans. Cyclomatic complexity and its properties :
- 1. Cyclomatic complexity is also known as structural complexity since it provides an interior perspective of the code.
- 2. This method is used to determine the number of independent pathways through a programme. This gives us an upper constraint on the number of tests that must be run to ensure that all statements have been executed at least once and that every condition has been executed on both its true and false sides.
- 3. If a programme has a backward branch, it may have an endless number of pathways. Although it is feasible to define a set of algebraic formulas that gives the total number of possible paths through a programme, employing total number of paths has been shown to be impractical.
- 4. As a result, the complexity measure is defined in terms of independent paths that, when combined, yield every potential path.
- 5. Each path through the programme that introduces at least one new set of processing statements or a new condition is considered an independent path.
- 6. McCabe’s cyclomatic metric, V(G) of a graph G with n vertices, e edges, and P connected components is
V(G) = e – n + 2P.
- 7. Given a programme, we will connect it to a directed network with distinct entrance and exit nodes. Each node in the graph corresponds to a sequential piece of code in the programme, and the arcs correspond to programme branching.
- 8. In this graph, it is expected that each node can be reached by the entry node and that each node can reach the exit node.
Meaning of cyclomatic complexity in tabular form :
- 1. There are various tools on the market that can compute cyclomatic complexity for large applications.
- 2. Nevertheless, estimating a module’s complexity after it has been constructed and tested may be too late.
- 3. It is possible that a sophisticated module cannot be redesigned after it has been tested.
- 4. As a result, before beginning the testing process, some fundamental complexity tests on the modules must be conducted.
- 5. Based on the complexity number that emerges from using the tool, one can conclude what actions need to be taken for complexity measure using the table given below :
Table.
| Complexity | What is means ? |
| 1 – 10 | Well-written code, testability is high, cost/ effort to maintain is low. |
| 10 – 20 | Moderately complex, testability is medium, cost/effort to maintain is medium. |
| 20 – 40 | Very complex, testability is low, cost/effort to maintain is high. |
| > 40 | Not testable, any amount of money effort to maintain may not be enough. |
Section 3 : Regression Test Selection in Software Testing
a. What are the categories to evaluate regression test selection techniques ? Why do we use such categorization ?
Ans. Regression test selection :
- 1. Due to expensive nature of “retest all” technique. Regression Test Selection (RTS) is performed.
- 2. In this technique instead of rerunning the whole test suite we select a part of test suite to rerun if the cost of selecting a part of test suite is less than the cost of running the tests that RTS allows us to on it.
- 3. RTS divides the existing test suite into :
- a. Reusable test cases
- b. Re-testable test cases
- c. Obsolete test cases.
- 4. In addition to this classification RTS may create new test cases that test the program for areas which are not covered by the existing test cases.
- 5. RTS techniqúes are broadly classified into three categories.
- a. Coverage approaches; they take into account the test coverage criteria. They identify coverable programme parts that have been modified and select test cases that are applicable to these parts.
- b. Minimization approaches: They are similar to coverage techniques in that they select the smallest number of test cases.
- c. Safe techniques: they do not focus on coverage criteria; instead, they choose all test cases that yield different results with a modified programme than with its original version.
- 6. There are various categories in which regression test selection technique can be evaluated and compared. These categories are :
- a. Inclusiveness;
- b. Precision;
- c. Efficiency;
- d. Generality.
- a. Inclusiveness is the extent to which a technique selects test cases that would cause the updated programme to give different output than the original programme, exposing defects related to alterations.
- b. Precision is a measure of a technique’s ability to avoid selecting test scenarios that may cause the altered programme to provide different results.
- c. Efficiency assesses a technique’s practicability (computational cost).
- d. Generality is a measure of a technique’s capacity to deal with complex alterations, realistic language constructs, and realistic testing applications.
Need of categorization: Categorization of regression test selection techniques is useful for choosing appropriate approaches for particular applications.
b. What is the difference between equivalence partitioning and boundary value analysis methods ?
Ans.
| S. No. | Equivalence class partitioning | Boundary value analysis |
| 1. | Equivalence class partition determines the number of test cases to be generated for a given scenario. | Boundary value analysis determines the effectiveness of those generated test cases. |
| 2. | In equivalence class, testing the input domain of-the program is partitioned into classes. | Here the test cases are generated using boundary values. |
| 3. | Equivalence class partition is nothing but to check the valid and invalid data of the field. | Boundary value analysis is nothing but to check the maximum and minimum length of the field. |
| 4. | The test cases are evaluated without considering single fault assumption of reliability. | Here single fault assumption of reliability is applied. |
| 5. | It determines the number of test cases generated for a program. | It determines the effectiveness of the test cases. |
Section 4 : Software Quality in Software Testing
a. What is software quality ? What are three dimensions of software quality ? Explain briefly.
Ans. Software quality is a field of study and practice that describe the desirable attributes of software products. It is concerned of the following:
- 1. Conformance of requirements.
- 2. Fitness for the purpose.
- 3. Level of satisfaction.
Three dimensions of software quality are :
- 1. Quality of design: It is the degree to which the design reflects a product or service that meets the demands and expectations of the customer. At the outlet, all of the relevant features should be built into the product or service.
- 2. Quality of conformance: It is the extent to which the product or service conforms to the design standard. The design has to be faithfully reproduced in the product or service.
- 3. Quality of use: It is the extent to which the user can ensure continued use of the product or service. Items must have a low cost of ownership, be safe and reliable, be easy to maintain, and be simple to use.
b. Explain equivalence class partitioning and boundary value analysis. Compare the two.
Ans. Equivalence class testing / Equivalence partitioning technique :
- 1. Equivalence partitioning is a software testing technique that identifies a small collection of typical input values that result in as many alternative output conditions as possible.
- 2. This decreases the amount of permutations and combinations of input and output values utilised for testing, boosting coverage while decreasing testing effort.
- 3. A partition is a collection of input values that produce a single predicted outcome.
- 4. When the programme behaves the same way for a collection of values, the set is referred to as an equivalence class or a partition.
- 5. In this instance, one representative sample from each partition (also known as an equivalence class member) is chosen for testing.
- 6. One sample from the partition is enough for testing as the result of picking up some more values from the set will be same and will not yield any additional defects.
- 7. Since all the values produce equal and same output, they are termed as equivalence partition.
- 8. Testing by this technique involves :
- a. identifying all partitions for the complete set of input, output values for a product and;
- b. picking up one member value from each partition for testing to maximize complete coverage.
- 9. From the results obtained for a member of an equivalence class or partition, this technique extrapolates the expected results for all the values in that partition.
- 10. The advantage of using this technique is that we gain good coverage with a small number of test cases.
- 11. By using this technique, redundancy of tests is minimized by not repeating the same tests for multiple values in the same partition.
Boundary value analysis :
- 1. Boundary value analysis is a technique for developing tests that are successful in detecting problems that occur at borders.
- 2. Boundary value analysis holds and expands on the idea that the density of faults is higher at the boundaries.
- 3. It has been discovered that most errors in situations like these occur around the boundaries.
- 4. While the reasons for this phenomenon is not entirely clear, some possible reasons are as follows :
- a. Programmers tentativeness in using the right comparison operator, for example : whether to use the < = operator or < operator when trying to make comparisons.
- b. Confusion caused by the availability of multiple ways to implement loops and condition checking.
- c. The requirements themselves may not be clearly understood, especially around the boundaries.
- 5. Boundary value analysis is highly effective in detecting flaws when internal constraints are imposed on certain resources, variables, or data structures.
- 6. Imagine a database management system that stores recently utilised data blocks in shared memory.
- 7. Typically, such a cached area is limited by a value that the user chooses when the system boots up.
- 8. When these buffers are filled and the next block needs to be cached, the buffer that was used the least recently – the first buffer – must be released after being stored in secondary memory.
- 9. Both the inserting of the new buffer and the release of the first buffer occur at the “boundaries.”
Section 5 : Black-Box Testing in Software Testing
a. What are the various types of errors detected in black-box testing ?
Ans. The black box testing is used to find the errors as follows:
- 1. Interface errors such as functions, which are unable to send or receive data from other software.
- 2. Incorrect functions that lead to undesired output when executed.
- 3. Missing functions and erroneous data structures.
- 4. Erroneous databases which lead to incorrect outputs when the software uses the data present in these databases for processing.
- 5. Incorrect conditions due to which the functions produce incorrect outputs when they are executed.
- 6. Termination errors such as certain conditions due to which a function enters a loop that forces it to execute indefinitely.
b. Differentiate between top down and bottom up integration testing.
Ans.
| Basis | Top-down integration testing | Bottom-up integration testing |
| Architectural Design | It discovers errors in high-level design, thus detects errors at an early stage. | High-level design is validated at a later stage. |
| System demonstration | The high level design gradually evolves into a working system as we integrate the elements from top to bottom. As a result, the systems’ practicality can be shown to upper management. | It may be impossible to demonstrate the design’s practicality. But, if some modules are already made reusable components, then some form of demonstration may be possible. |
| Test implementation | Stubs are required for the subordinate modules. | Test drivers are required for super ordinate modules to test the lower-level modules. |
Section 6 : Structured Programming in Software Testing
a. What is the difference between system testing and acceptance testing ?
Ans.
| S. No. | System testing | Acceptance testing |
| 1. | System testing is end-to-end testing performed to see whether the programme fits the criteria. | Acceptance testing is performed to determine whether the programme meets the needs of the customer. |
| 2. | System testing is performed by developers and testers. | Acceptance testing is performed by independent set of testers and also the stakeholders, clients. |
| 3. | System testing can be both functional and non-functional testing. | Acceptance testing is pure functional testing. |
| 4. | System testing examines how the system as a whole behaves, as well as the functionality and performance. | In acceptance testing we check if the system is meeting the business needs of the organization, usability of the product. |
| 5. | It is performed with demo data and not the production data. | It is performed with the actual real time data, production data. |
| 6. | In this testing we test the software for complete specification including hardware and software, memory and number of users. | Here we test the software for the user needs and if user needs are net in the developed software. |
| 7. | System testing comprises of system testing and system integration testing. | Acceptance testing comprises of alpha testing and beta testing. |
| 8. | System testing is performed before the acceptance testing. | Acceptance testing is performed after the system testing. |
| 9. | The defects found in system testing can be fixed based on priorities. | The defects found in acceptance testing are taken as failure product. |
b. What is structured programming ? Why it is important ?
Ans.
- 1. Structured programming (also known as modular programming) is a subset of procedural programming that imposes a logical structure on the programme being created in order to make it more efficient, understandable, and easy to adapt.
- 2. Several programming languages, such as Ada, Pascal, and dBASE, provide features that encourage or enforce logical programme organisation.
- 3. Structured programming usually uses a top-down design style, in which developers divide the entire programme structure into subsections.
- 4. A defined function or collection of related functions is coded in its own module or submodule, allowing code to be loaded into memory more efficiently and modules to be reused in other systems.
- 5. After a module has been tested individually, it is then integrated with other modules into the overall program structure.
- 6. Program flow follows a simple hierarchical model that employs looping constructs such as “for,” “repeat,” and “while.” Use of the “Go To” statement is discouraged.
It is important because using structured programming languages have the following advantages :
- 1. Programs are easier to read and understand.
- 2. Application programs are less likely to contain logic errors.
- 3. Errors are more easily found.
- 4. Higher productivity during application program development.
- 5. Application programs are more easily maintained.
- 6. Identify modifications for additional functions or correcting errors.
Section 7 : Risk Matrix in Software Testing
a. Explain how risk matrix can be used to prioritize the test cases ?
Ans. Risk matrix :
- 1. A risk matrix enables the tester to analyse and rank probable problems by assigning a higher weight to the likelihood or severity value as needed.
- 2. The use of a risk matrix ignores risk exposure. The risk matrix is used by the tester to assign thresholds that categorise probable problems into priority categories.
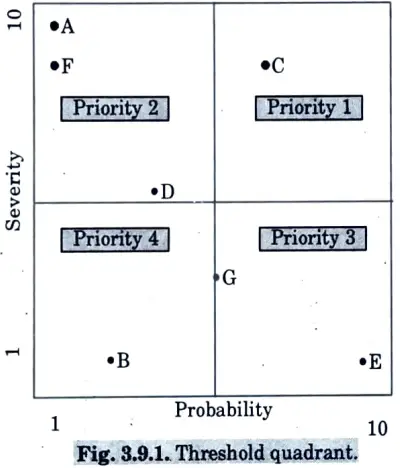
- 3. Typically, the risk matrix contains four quadrants, as shown in Fig. 3.9.1, with each quadrant representing a priority class defined as follows :
- Priority 1: high severity and high probability.
- Priority 2: high severity and low probability.
- Priority 3: low severity and high probability.
- Priority 4: low severity and low probability.
- 4. In this particular example, a risk with high severity is deemed more important than a problem with high probability. Thus, all risks mapped in the upper left quadrant fall into Priority 2.
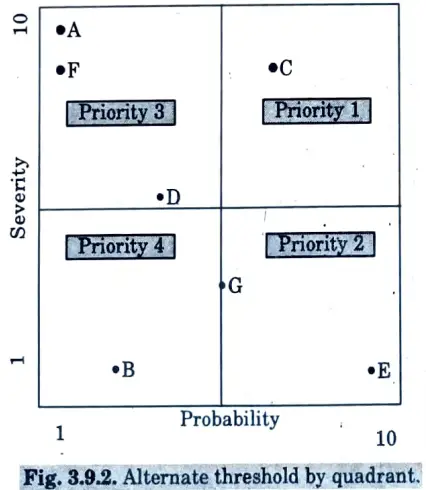
- 5. For an entirely different application, the consensus may be to swap the definitions of Priorities 2 and 3, as shown in Fig. 3.9.2.
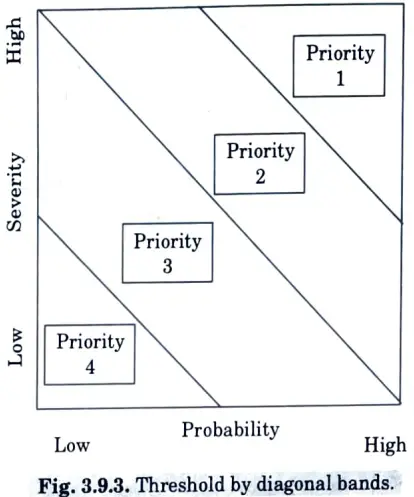
- 6. An organization favouring Fig. 3.9.3, seeks to minimize the total number of defects by focusing on problems with a high probability of occurrence.
- 7. Although it is most customary to divide a risk matrix into quadrants, testers can calculate thresholds using alternative sorts of boundaries based on application-specific considerations.
- 8. The ideal threshold restrictions are sometimes those that both assuage management concerns and fulfil customer wants.
- 9. If severity and probability are roughly similar, a diagonal band priority strategy, as shown in Fig. 3.9.3, may be preferable.
- 10. This threshold pattern is a workaround for individuals who can’t decide between Priority 2 and Priority 3 in the quadrant method.
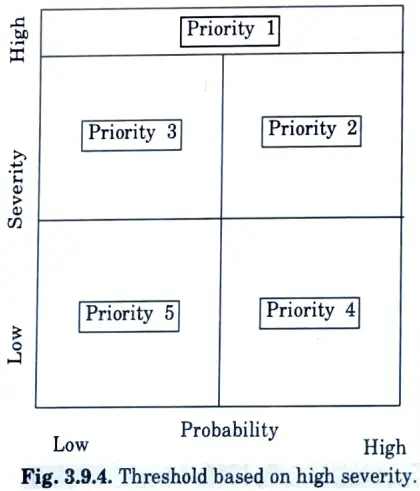
- 11. Some managers are concerned that neglecting any problem of high severity, regardless of likelihood, could expose the firm to liability for carelessness.
- 12. The prioritization scheme shown in Fig.3.9.4 addresses this concern by assigning top priority to all high severity problems.
- 13. The remainder of the risk matrix is partitioned into several lower priorities, whether as quadrants or diagonal bands.
b. What do you mean by Big-bang’ integration strategy ?
Ans.
- 1. In big bang integration, one tests each of the modules independently.
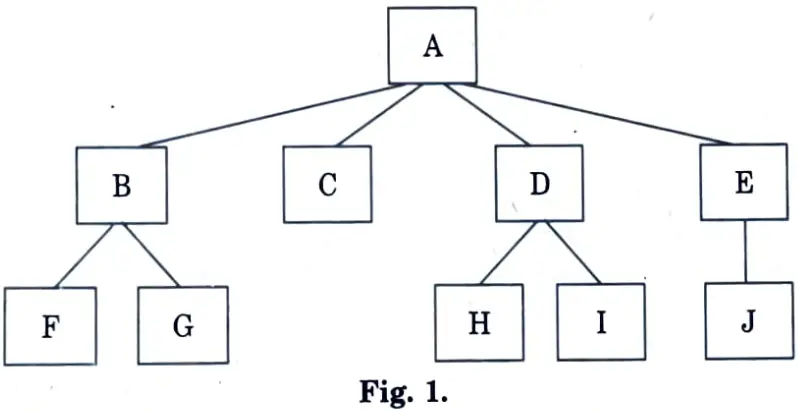
- 2. Each of the 10 modules A-J of Fig. 1 is tested independent of the others.
- 3. Once this testing is completed, the modules are assembled and the full programme is tested.
- 4. Because the individual modules were evaluated before being combined together, all logic faults within the modules should have been resolved before testing of the overall programme begins.
- 5. As a result, when the integrated software is examined, one may only expect to find interface-related issues.
- 6. However, because testing is limited to a subset of all possible inputs, logic flaws inside a module may be found even while testing the overall programme.
- 7. When utilising the big-bang technique, identifying failure sources and rectifying faults becomes more challenging as the system becomes more complicated.
- 8. One may use this strategy when the number of components involved is small and each is relatively simple.