
The AKTU Distributed Systems question paper with answers is a comprehensive collection of exam-style questions and lengthy explanations that will help B.Tech students prepare for distributed systems examinations.
Dudes 🤔.. You want more useful details regarding this subject. Please keep in mind this as well. Important Questions For Distributed Systems: *Quantum *B.tech-Syllabus *Circulars *B.tech AKTU RESULT * Btech 4th Year
Section A: Short Question Distributed System Aktu
a. Define bully algorithm.
Ans. The Bully algorithm is a method for selecting a coordinator or leader from a collection of distributed computer processes on the fly. The coordinator is chosen from among the non-failed processes with the highest process ID number.
b. Differentiate between 2PL and strict 2PL.
Ans.
| S. No. | 2PL | Strict 2PL |
| 1. | A transaction in 2PL must get locks on all the data elements it requires before it can begin execution. | A transaction in strict 2PL can acquire locks on data items anytime it has to (just during the growth phase) during its execution. |
| 2. | It does not have growing phase. | It has growing phase. |
| 3. | It has shrinking phase. | It has partial shrinking phase. |
c. Explain token based algorithm.
Ans. 1. A unique token is shared by all sites in the token-based algorithm. If a site has the token, it is permitted to enter its CS (Critical Section).
2. Sequence numbers are used instead of timestamps in token-based algorithms.
3. Each token request has a sequence number, and each site’s sequence number progresses independently. Every time a site requests a token, it increments its sequence number counter.
d. What is the election algorithm ?
Ans. To operate as a coordinator, election algorithms select a process from a collection of processors. If the coordinator process fails for any reason, a new coordinator is chosen on another processor. The election algorithm determines where a new copy of the coordinator should be begun.
e. What is meant by nested transactions ?
Ans. A nested transaction is an extension of the transaction model. It allows a transaction to contain other transactions.
f. Define Edge chasing.
Ans.
- 1. The edge chasing approach is used in distributed systems to remove phantom deadlocks.
- 2. The global wait-for-graph is not formed in this case, but each of the servers involved is aware of some of its edges.
- 3. The servers try to discover cycles by sending messages called probes that follow the graph’s edges throughout the distributed system.
- 4. A probe message is made up of transactional wait-for-relationships, each of which represents a path in the global wait-for-graph.
g. What is deadlock resolution ?
Ans. The resolution of deadlocks includes breaking existing wait-for dependencies in the system WFG. It entails rolling many deadlocked processes and transferring their resources to the stuck processes so that they can resume execution.
h. Describe orphan message and loss message.
Ans. Orphan message: Orphan messages are messages with “receive” recorded but message “send” not recorded.
Lost message: Lost messages are messages whose “send” is done but “receive” is undone due to rollback.
i. Explain event ordering.
Ans. Event ordering in Distributed Systems (DS) is the process of assigning a specific order to events that occur based on specified criteria. No order, FIFO, causal, D-causal, total, and causal-total are the event orderings utilised for DS.
j. What do you mean by global state of distribution system ?
Ans. A distributed computation’s global state is the set of local states of all individual processes involved in the computation as well as the state of the communication channels. The global state of the system is a collection of a processing system’s local states.
GS = {LS1, LS2, LS3…..LSN}
where N is the number of sites in the system.
Section B : Briefly Discussed Questions in Distributed System
a. What are phantom deadlock ? Explain the algorithm which could detect phantom deadlock.
Ans. Phantom deadlock :
- 1. A phantom deadlock is one that is ‘detected’ but is not actually a stalemate.
- 2. Information regarding wait-for linkages between transactions is transferred from one server to another in distributed deadlock detection.
- 3. If a deadlock occurs, the essential information will finally be gathered in one location, and a cycle will be noticed.
- 4. Because this method will take some time, there is a potential that one of the transactions holding a lock will have released it in the meantime, in which case the deadlock will no longer exist.
Phantom deadlock detection algorithm :
- 1. Centralized control :
- a. A selected site (control site) is in charge of creating the global WFG and scanning it for cycles in centralised deadlock detection techniques.
- b. Centralized deadlock detection techniques are conceptually straightforward and straightforward to implement.
- 2. Distributed control :
- a. In these algorithms, all sites share equal responsibility for identifying a global stalemate.
- b. The global state graph is distributed over several sites, and multiple sites contribute to the identification of a global cycle.
- 3. Hierarchical control: Sites are grouped hierarchically in hierarchical deadlock detection methods, and a site detects deadlocks involving only its descendent sites.
b. Describe the advantages and disadvantages of the HTML, URL and HTTP as core technologies for information browsing.
Ans. Advantages of HTML :
- 1. Every browser supports HTML Language.
- 2. Easy to learn and use.
- 3. HTML is light weighted and fast to load.
- 4. Do not get to purchase any extra software because it’s by default in every window.
Disadvantages of HTML :
- 1. It cannot produce dynamic output alone, since it’s a static language.
- 2. Making the structure of HTML documents becomes tough to understand.
- 3. Errors can be costly.
- 4. It is the time consuming as the time it consume to maintain on the colour scheme of a page and to make lists, tables and forms.
Advantages of HTTP :
- 1. It offers lower CPU and memory usage due to less simultaneous connections.
- 2. It enables HTTP pipelining of requests/responses.
- 3. It offers reduced network congestion as there are fewer TCP connections.
- 4. Handshaking is done at the initial connection establishment stage. Hence it offers reduced latency in subsequent requests as there is no handshaking.
Disadvantages of HTTP :
- 1. It can be used for point to point connection.
- 2. It is not optimized for mobile.
- 3. It does not have push capabilities.
- 4. It does not offer reliable exchange.
Advantages of URL :
- 1. Improved user experience: A well-crafted URL gives humans and search engines a clear indicator of what the destination page will be about.
- 2. Rankings: URLs are a minor ranking element used by search engines to determine the relevancy of a certain page or resource to a search query. While they do add weight to the overall domain’s authority, keyword inclusion in a URL can also be a ranking factor.
- 3. Links: When copied and pasted as links in forums, blogs, social media networks, or other online arenas, well-written URLs can function as their own anchor text.
Disadvantages of URL :
- 1. Certain URLs are unsuitable for generating traction and sharing. These may appear as spam, especially if they are designed to attract additional attention.
- 2. URLs do not help to evoke trust because more experienced users realise it is not a good option as a URL shortening service.
- 3. Certain URLs cannot be altered at all, which may cause your URL to appear spammy.
- 4. Certain URLs do not use click tracking to measure and track how visitors interact with your website.
- 5. Certain Websites, as well as access to RSS feeds and spreadsheets, are problematic for statistics.
- 6. No bookmarking service is provided for the URL; this feature is useful because you cannot save URLs for later use.
- 7. Some URL has unique domain names, especially if you are trying to create a short, simple link.
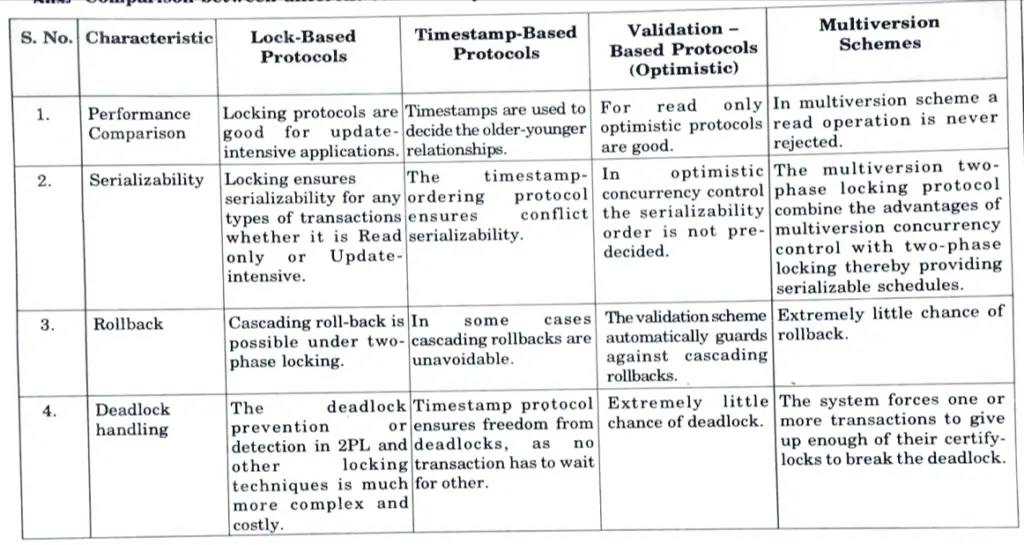
c. Write compare and contrast between different concurrency control techniques for transaction.
Ans. Comparison between different concurrency control techniques :
d. Discuss any checkpoint and recovery algorithm that takes a consistent checkpoint and avoids livelock problems.
Ans. Checkpoint algorithm : Synchronous checkpointing :
- 1. In this approach, processes synchronize their checkpointing activity so that a globally consistent set of checkpoints is always maintained in the system.
- 2. In this method, consistent set of checkpoints are used which avoids livelock problems during recovery.
Algorithm :
- 1. It assumes the following characteristics :
- a. Processes communicate by exchanging messages through communication channels.
- b. Channels are FIFO in nature.
- c. Communication failures do not partition the network.
- 2. The checkpoint algorithm takes two kinds of checkpoints on stable storage :
- a. Permanent checkpoint: A permanent checkpoint is a process-specific checkpoint that is part of a consistent global checkpoint.
- b. Tentative checkpoints: A tentative checkpoint is a temporary checkpoint that becomes a permanent checkpoint when the checkpoint algorithm is successfully terminated.
- 3. Processes rollback only to their permanent checkpoints.
- 4. The algorithm has two phases :
- a. First phase:
- i. An initiating process Pi takes tentative checkpoint and requests all the processes to take tentative checkpoints.
- ii. Each process informs process Pi whether it accepts or rejects the request of taking tentative checkpoint.
- iii. When all the process has successfully accepted the tentative checkpoints then Pi decides to make this checkpoint a permanent checkpoint. Otherwise tentative checkpoint is discarded.
- b. Second phase :
- i. Pi informs all the processes of the decision it reached at the end of the first phase.
- ii. A process, on receiving the message from Pi, will act accordingly.
- iii. Therefore, either all or none of the processes accept permanent checkpoints.
Recovery algorithm :
- 1. This approach requires that a single process invokes it rather than numerous processes invoking it concurrently to rollback and Failure Recovery in Distributed System recover.
- 2. It also assumes that the checkpoint and rollback recovery methods are not called at the same time.
- 3. This algorithm has two phases :
- a. First phase :
- i. An initiating process Pi checks whether all the processes are willing to restart from their previous checkpoints.
- ii. A process may reject the request of Pi if it is already participating in a checkpointing or a recovering process initiated by some other process.
- iii. If all the processes accept the request of Pi to restart from their previous checkpoints, Pi decides to restart all the processes.
- iv. Otherwise all the processes continue with their normal activities.
- b. Second phase :
- i. Pi propagates its decision to all the processes. On receiving Pi‘s decision, a process will act accordingly.
- ii. The recovery algorithm requires that every process do not send messages related to underlying computation while it is waiting for Pi‘s decision.
e. Differentiate between forward and backward recovery. Explain Orphan Message and Domino effect with example.
Ans. Difference between forward and backward recovery :
| S. No. | Forward Recovery | Backward Recovery |
| 1. | Forward error recovery attempts to recover a consistent state from partially inconsistent data. | After detecting an inconsistency (fault), the notion of backward recovery is to revert to a previous consistent system state. |
| 2. | In forward recovery if any error occurs then it removes the error and continue the process. | In backward recovery if any error occurs then it restarted that process. |
| 3. | Forward recovery is difficult to implement. | Backward recovery is simpler to implement. |
| 4. | In order to handle mistakes, forward error recovery is often utilised in composite web services. | Backward error recovery is not suitable for composite web services. |
| 5. | Because forward recovery removes the error and continues the process, it ensures that the issue does not reoccur. | In the retrograde recovery, there is no such conformation. |
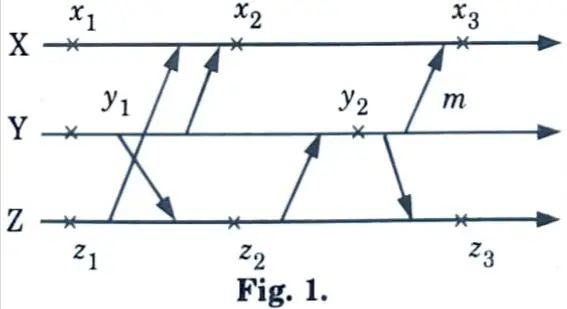
Orphan message: An orphan message is a message whose receiving event is recorded in the checkpoint, but its sending event is not. For e.g., orphan message ‘m’ is created due to the rollback of process Y to checkpoint y2.
Domino effect: When one rollback causes other to roll back; e.g., when Y goes back to checkpoint y2.
Section 3 : Network Partition in Distributed System
a. Which protocol do you suggest when there is a network partition ? Explain it’s variant as well.
Ans.
- 1. Atomic commit protocols can handle network partitions.
- 2. Network partitions are caused by communication line failures and may result in message loss, depending on how the communication subnet is implemented.
- 3. A partitioning is referred to be simple if the network is partitioned into only two components; otherwise, it is referred to as multiple partitioning.
- 4. Network partitioning termination methods address the termination of transactions that were active in each partition at the time of partitioning.
- 5. Following two protocols are used as termination protocols for network partitioning :
- A. Centralized Protocols :
- 1. The centralised concurrency control techniques underpin centralised termination protocols.
- 2. The functioning of the partition containing the central site is permitted in the centralised protocol since it handles the lock tables.
- 3. Each data item’s primary site strategies are consolidated.
- 4. In this instance, multiple partitions may be active for distinct queries.
- 5. Both of these straightforward ways are dependent on the distributed database manager’s concurrency control mechanism.
- B. Voting-based Protocols :
- 1. The core notion behind a voting-based protocol is that a transaction is conducted if a majority of the sites decide to do so.
- 2. The concept of majority voting has been extended to quorum voting.
- 3. In the presence of network partitioning, quorum-based voting can be utilised as a replica control method as well as a commit method to assure transaction atomicity.
- 4. For non-replicated databases, this entails integrating the voting concept with commit mechanisms.
b. Explain how a non-recoverable situation could arise if write locks are released after the last operation of a transaction but before its commitment.
Ans.
- 1. An earlier transaction may release its locks but not commit; in the meanwhile, a subsequent transaction utilises the objects and commits.
- 2. The previous transaction may then fail.
- 3. The subsequent transaction performed a dirty read and is no longer recoverable because it has already committed.
- 4. It simply says that if the write locks are released before the data is stored, a new transaction may come along, use the data, modify its value, and then commit before the original transaction commits.
- 5. After that, when the first transaction completes, it commits.
- 6. There are two difficulties here: the data read by the second transaction is old data, while the data read by the first transaction is new data (in ideal situation it should have used the value which the first transaction provides).
- 7. Another issue is that when the first transaction completes its commit, the second transaction’s commit is lost.
Section 4 : Chandy-Lamport Algorithm in Distributed System
a. Explain Chandy-Lamport algorithm for consistent state recording.
Ans. Chandy-Lamport global state recording algorithm :
- 1. The Chandy-Lamport method employs a control message known as a marker, which serves to segregate messages in a FIFO system.
- 2. After recording its local state, a site sends a marker along all of its outbound channels before delivering any further messages.
- 3. A marker distinguishes between messages in the channel that are to be recorded in the local state and those that are not to be recorded in the local state.
- 4. Before receiving a marker on any of its incoming channels, a process must record its local state.
Chandy-Lamport algorithm :
1. Marker receiving rule for process j :
On receiving a marker along channel C:
If (j has not recorded its state) then
Record its process state
Record the state of C as the empty set
Follow the “marker sending rule”
else
Record the state of C as the set of messages received along C after j’s state was recorded and before j received the marker along C.
2. Marker sending rule for process i :
- a. Process i records its state.
- b. For each outgoing channel C on which a marker has not been sent, i sends a marker along C before i sends further messages along C.
b. What are distributed systems ? What are the significant advantages and applications of distributed systems ?
Ans. Distributed system :
- 1. A distributed system is one in which software or hardware components linked by a communication network communicate and coordinate their operations solely through message passing.
- 2. Computers that are connected by a network may be spatially separated by distance
- 3. Resources may be managed by servers and accessed by clients.
Advantages of distributed system :
- 1. Data sharing: It allows many users to access to a common database.
- 2. Resource sharing: Expensive peripherals like color printers can be shared among different nodes (or systems).
- 3. Communication: Enhance human-to-human communication, e.g., email, chat.
- 4. Flexibility: Spread the workload over the available machines.
Applications of distributed systems :
- 1. Telecommunication networks such as telephone networks and cellular networks.
- 2. Network applications, world wide web and peer-to-peer networks.
- 3. Real-time process controls aircraft control systems.
- 4. Parallel computation.
Section 5 : Timestamp Ordering in Distributed System
a. What is Timestamp ordering ? Explain advantages and disadvantages of multi-version time stamp ordering.
Ans. Timestamp ordering :
- 1. In a distributed transaction, each coordinator generates timestamps that are globally unique.
- 2. The first coordinator accessed by a transaction issues a globally unique transaction timestamp to the client.
- 3. The transaction timestamp is sent to the coordinator at each server whose objects participate in the transaction.
- 4. Distributed transaction servers are jointly accountable for guaranteeing that they are processed serially equivalently.
- 5. A timestamp consists of a pair < local timestamp, server-id >.
- 6. The agreed-upon ordering of pairs of timestamps is based on a comparison where the server-id component is less important.
- 7. Even if their local clocks are not synced, all servers can achieve the same transaction ordering.
Advantages of multiversion timestamp ordering :
- 1. It allows more concurrency in distributed system.
- 2. Improved system responsiveness by providing multiple versions.
- 3. Reduces the probability of conflicts transaction.
- 4. Read request never fails and is never made to wait.
Disadvantages of multiversion timestamp ordering :
- 1. Reading of a data item also requires the updating of the read timestamp field resulting in two potential disk accesses, rather than one.
- 2. The conflicts between transactions are resolved through rollbacks, rather than through waits.
- 3. It require huge amount of storage for storing multiple versions of data objects.
- 4. It does not ensure recoverability and cascadelessness.
b. Discuss the followings terms:
i. Highly available services.
ii. Sequential Consistency.
Ans. i. Highly available services :
- 1. Service availability refers to the proportion of time that a service is operational.
- 2. A highly available service is one that is close to 100% available with a tolerable response time.
- 3. It may not follow the rules of sequential consistency.
- 4. The gossip architecture is a methodology for developing highly available services by replicating data near to where groups of clients require it.
ii. Sequential Consistency :
- 1. Sequential consistency is a high level of safety in concurrent systems.
- 2. A system is sequentially consistent if the result of any execution of all the processors’ operations is the same as if they were run sequentially, and the actions of each individual processor appear in this sequence in the order provided by its programme.
- 3. It implies that operations appear to occur in some overall order that is consistent with the order of operations on each individual process.
- 4. Sequential consistency is not always available; if a network partition occurs, some or all nodes will be unable to progress.
Section 6 : Agreement Protocol in Distributed System
a. What do you mean by agreement protocol? List all the agreement protocols and the difference between them.
Ans. Agreement protocols :
- 1. The agreement protocol refers to the process of transmitting and reaching an agreement to all locations.
- 2. Agreement protocols are extremely important in distributed systems for error-free communication among diverse sites.
- 3. Faulty processors are more likely in distributed systems. A defective processor may result in incorrect message communication, no response to a message, and so on.
- 4. The presence of a faulty CPU is also unknown to non-faulty processors. As a result, the non-problematic processors do not prevent message flow to the faulty processors.
- 5. The agreement protocols enable non-defective processors in the distributed system to achieve a common agreement, regardless of whether other processors are faulty or not.
- 6. The common agreement among the processors is taken through the agreement protocol.
Classification of agreement protocol :
- 1. The Byzantine agreement problem :
- a. In the Byzantine agreement problem, a randomly selected processor, known as the source processor, broadcasts its initial value to all other processors.
- b. A solution to the Byzantine agreement problem should meet the following objectives :
- i. Agreement: All non-faulty processors agree on the same value.
- ii. Validity: If the source processor is non-faulty, then the common agreed upon value by all non-faulty processors should be the initial value of the source.
- iii. Termination: Each non-faulty processor must eventually decide on a value.
- 2. Consensus problem :
- a. In the consensus problem, every processor broadcasts its initial value to all other processors.
- b. Initial values of the processors may be different.
- c. A protocol for reaching consensus should meet the following conditions :
- i. Agreement: All non-faulty processors agree on the same single value.
- ii. Validity: If the initial value of every non-faulty processor is v, then the agreed upon common value by all non-faulty processors must be v.
- iii. Termination: Each non-faulty processor must eventually decide on a value.
- 3. The interactive consistency problem :
- a. In the interactive consistency problem, every processor broadcasts its initial value to all other processors.
- b. The initial values of the processors may be different.
- c. A protocol for the interactive consistency problem should meet the following conditions :
- i. Agreement: All non-faulty processors agree on the same vector (v1, v2,…vn).
- ii. Validity: If the ith processor is non-faulty and its initial value is vi, then the ith value to be agreed on by all non-faulty processors must be vi.
- iii. Termination: Each non-faulty processor must eventually decide on different value of vectors.
b. What are the fault tolerance service available now days ? Explain in detail.
Ans. 1. Fault tolerant services are obtained by using replication.
2. Using many independent server replicas, each of which manages duplicated data, aids in the design of a service that demonstrates graceful degradation after partial failure and improves overall server performance.
Following are two main fault-tolerance service models :
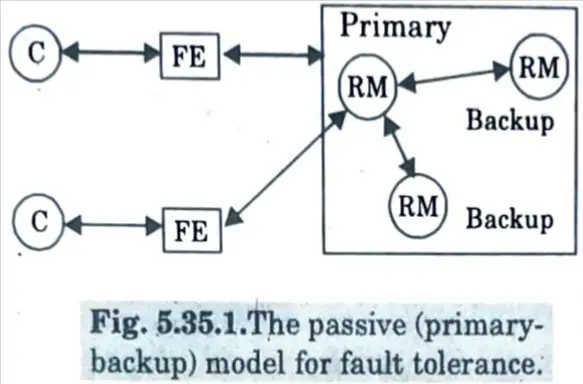
1. Passive (primary-backup) replication :
- a. In a passive replication architecture for fault tolerance, there is always a single primary replica manager and one or more secondary replica managers, sometimes known as “backups” or “slaves.”
- b. In its purest version, the model requires front ends to communicate solely with the primary replica manager in order to receive the service.
- c. The primary replica manager performs the actions and delivers updated data copies to the backups.
- d. If the primary fails, one of the backups is promoted to act as the primary.
- e. The sequence of events when a client requests an operation to be performed is as follows :
- i. Request: The front end issues the request, containing a unique idèntifier, to the primary replica manager.
- ii. Coordination: The main processes each request in the sequence in which it is received. If it has previously processed the request, it validates the unique identification and simply re-sends the response.
- iii. Execution: The primary executes the request and stores the response.
- iv. Agreement: If the request is an update then the primary sends the updated state, the response and the unique identifier to all the backups. The backups send an acknowledgement.
- v. Response: The primary responds to the front end, which hands the response back to the client.
2. Active replication :
- a. The replica managers in the active model of replication for fault tolerance are state machines that play equivalent roles and are structured as a group.
- b. Front ends multicast their requests to a collection of replica managers, and all replica managers independently but identically process and respond to the request.
- c. If any replica manager fails, the service will continue to function normally because the remaining replica managers will continue to respond normally
- d. Under active replication, the sequence of events when a client requests and operation to be performed is as follows :
- i. Request: The front end attaches a unique identifier to the request and multicasts it to the group of replica managers, using a totally ordered, reliable multicast primitive.
- ii. Coordination: The group communication system delivers the request to every correct replica manager in the same (total) order.
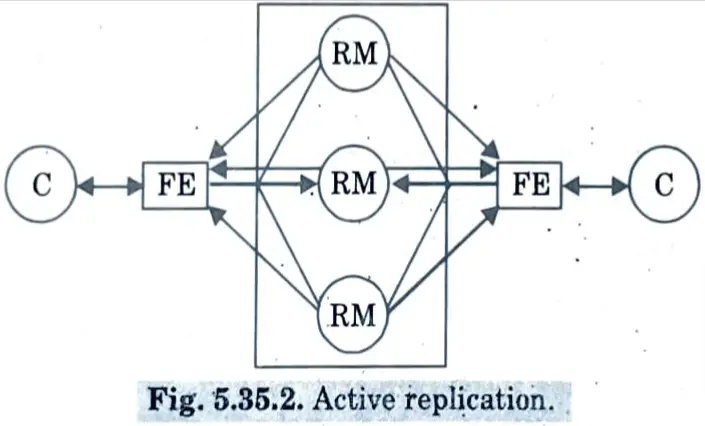
- iii. Execution: Every replica manager executes the request.
- iv. Agreement: No agreement phase is needed, because of the multicast delivery semantics.
- v. Response: Each replica manager sends its response to the front end.
Section 7 : Deadlock Detection in Distributed System
a. How distributed mutual exclusion is different of mutual exclusion in single computer system ? Explain Ricart Agrawala Algorithm.
Ans. Difference :
| S. No. | Mutual exclusion in distributed system | Mutual exclusion in single-computer |
| 1. | Shared memory dóes not exist. | Shared memory exists. |
| 2. | Both shared resources and the users may be distributed. | Both shared resources and the users are present in shared memory. |
| 3. | Mutual exclusion problem is solved by using message passing approach. | Mutual exclusion problem is solved by using shared variables approach i.e., semaphores. |
Ricart-agrawala : The Ricart-Agrawala algorithm is an optimization of Lamport’s algorithm that dispenses with RELEASE messages by merging them with REPLY messages. In this algorithm,
∀ i : 1 ≤ i ≤ N ∷ Ri = (S1, S2,…SN)
Algorithm :
- 1. Requesting the critical section :
- a. When a site Si wants to enter the CS, it sends a timestamped REQUEST message to all the sites in its request set.
- b. When site S, receives a REQUEST message from site Si, it sends a REPLY message to site Si, if site Sj is neither requesting nor executing the CS or if site Sj is requesting and Si‘s request’s timestamp is smaller than site Sj’s own request’s timestamp. The request is deferred otherwise.
- 2. Executing the critical section :
- a. Site Si enters the CS after it has received REPLY messages from all the sites in its request set.
- 3. Releasing the critical section :
- a. When site Si exits the CS, it sends REPLY message to all the deferred requests.
A site’s REPLY messages are blocked only by sites that are requesting the CS with higher priority (i.e. a smaller timestamp). Thus, when a site sends out REPLY messages to all the deferred requests, the site with the next highest priority request receives the last needed REPLY message and enters the CS. The execution of CS requests in this algorithm is always in the order of their timestamps.
Performance: The Ricart-Agrawala algorithm requires 2(N – 1) messages per CS execution : (N – 1) REQUEST and (N – 1) REPLY messages. Synchronization delay in the algorithm is T.
b. Explain path pushing algorithm for distributed deadlock detection algorithm.
Ans. Distributed deadlock detection algorithms can be divided into four classes :
- a. Path-pushing algorithm: In path-pushing algorithms, wait for dependency information of the global WFG (wait for graph) is circulated in the form of paths.
- b. Edge chasing algorithm: In edge chasing algorithms, special messages called probes are circulated along the edge of the WFG to detect a cycle. When a blocked process receives a probe, it propagates the probe along its outgoing edges in the WFG.
- c. Diffusion computation based algorithm: Diffusion computation type algorithms make use of echo algorithms to detect deadlocks.
- Deadlock detection messages are successively propagated (i.e., “diffused”) through the edges of the WFG.
- d. Global state detection based algorithm: These algorithms detect deadlocks by taking a snapshot of the system and by examining it for the condition of a deadlock. Several sites in distributed system participate in detection of global cycle. Thus global state graph is spread over many sites. The responsibility of detecting deadlock is shared equally among all sites.
Obermarck’s path-pushing algorithm :
- 1. Obermarck’s push-pushing algorithm was designed for distributed database system.
- 2. In path-pushing deadlock detection algorithms, information about the wait-for dependencies is propagated in the form of a path.
Algorithm: Deadlock detection at a site follows the following iterative process :
- 1. The sites wait for deadlock-related information from other sites in the system.
- 2. The site combines the received information with its local TWF graph to build an updated TWF graph. It then detects all cycles and breaks local cycles which do not contain the node Ex (External node).
- 3. For all cycles, ‘Ex → T1 → T2 → Ex’ which contains the node ‘Ex’ the site transmits them in string form ‘Ex T1, T2, Ex’ to all other sites where a subtransaction of T2 is waiting to receive a message from the subtransaction of T2 at this site. The algorithm reduces message traffic by lexically ordering transaction and sending the string ‘Ex, T1, T2, T3 Ex’ to other sites only if T1 is higher than T3 in the lexical ordering. Also, for a deadlock, the highest priority transaction detects the deadlock.
1 thought on “AKTU Question Paper with Answers: Distributed Systems”