
With the help of our AKTU question paper and solution, explore into the field of Database Management System. To gain a full understanding of data organisation and retrieval, consult comprehensive PDFs and quantum notes.
Dudes 🤔.. You want more useful details regarding this subject. Please keep in mind this as well. Important Questions For Database Management System: *Quantum *B.tech-Syllabus *Circulars *B.tech AKTU RESULT * Btech 3rd Year
Section A: Database Management System Short Notes
a. What is the significance of Physical Data Independence?
Ans. Physical data independence helps you to separate conceptual levels from the internal/physical levels. It allows you to provide a logical description of the database without the need to specify physical structures.
b. List the four functions of DBA.
Ans.
- 1. Schema definition
- 2. Storage structure and access method definition
- 3. Schema and physical organization and modification
- 4. Granting of authorization for data access
c. When a relation set is called a recursive relationship set ?
Ans. When there is a relationship between two entities of the same type, it is known as a recursive relationship. This means hat the relationship is between different instances of the same entity type.
d. What do you mean by currency with respect to database ?
Ans. The DBMS uses currency to keep track of the database location (db-key) of the most recently accessed record occurrences for the run unit, record type, set, and area. By keeping track of the most recently accessed records, currency enables you to navigate the database with a minimum of effort.
e. What is Relational Calculus ?
Ans.
- 1. Relational calculus is a non-procedural query language.
- 2. Relational calculus is a query system where queries are expressed as formulas consisting of a number of variables and an expression involving these variables.
- 3. In a relational calculus, there is no description of how to evaluate a query.
f. What is Equi-Join in database?
Ans. An equi-join is a type of join that combines tables based on matching values in specified columns. The column names do not need to be the same. The resultant table contains repeated columns. It is possible to perform an equi-join on more than two tables.
g. What is a CLAUSE in terms of SQL ?
Ans. A CLAUSE in SQL is a part of a query that lets us filter or customizes how we want our data to be queried to us.
h. Define the closure of an attribute set.
Ans. The closure of a set of attributes X is the set of those attributes that can be functionally determined from X. The closure of X is denoted as X+ When given a closure problem, we’ll have a set of functional dependencies over which to compute the closure and the set X for which to find the closure.
i. When is a transaction Rolled Back ?
Ans. A rollback is the operation of restoring a database to a previous state by canceling a specific transaction or transaction set. Rollbacks are either performed automatically by database systems or manually by users.
j. List the various levels of locking?
Ans. Levels of Locking in DBMS:
- 1. Database Level
- 2. Table Level
- 3. Page Level
- 4. Row Level
Section B: Database Management System Important Notes
a. Draw the overall structure of DBMS and explain its various components.
Ans. A database system is partitioned into modules that deal with each of the responsibilities of the overall system. The functional components of a database system can be broadly divided into two components:
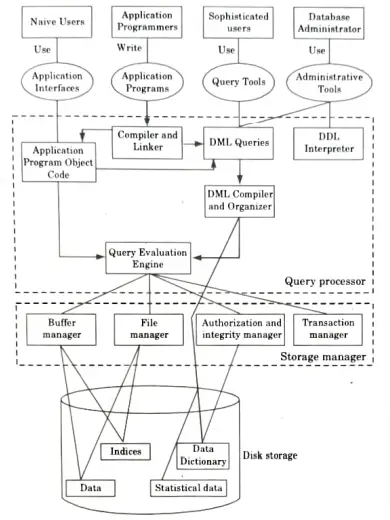
1. Storage Manager (SM): A storage manager is a program module that provides the interface between the low level data stored in the database and the application programs and queries submitted to the system. The SM components include:
- a. Authorization and integrity manager: It tests for the satisfaction of integrity constraints and checks the authority of users to access data.
- b. Transaction manager: It ensures that the database remains in a consistent state despite of system failures and that concurrent transaction executions proceed without conflicting.
- c. File manager: It manages the allocation of space on disk storage and the data structures are used to represent information stored on disk.
- d. Buffer manager: It is responsible for fetching data from disk storage into main memory and deciding what data to cache in main memory. The buffer manager is a critical part of the database system, since it enables the database to handle data sizes that are much larger than the size of main memory.
2. Query Processor (QP): The Query Processor (Query Optimizer) is responsible for taking every statement sent to SQL Server and figure out how to get the requested data or perform the requested operation.
The QP components are:
- a. DDL interpreter: It interprets DDL statements and records the definition in data dictionary.
- b. DML compiler: It translates DML statements in a query language into an evaluation plan consisting of low-level instructions that the query evaluation engine understands.
- c. Query optimization: It picks the lowest cost evaluation plan from among the alternatives.
- d. Query evaluation engine: It executes low-level instructions generated by the DML compiler.
b. Which relational algebra operations require the participating tables to be union-compatible ? Give the reason in detail.
Ans. 1. The basic relational algebraic operations are the four set operations: UNION, INTERSECTION, SET DIFFERENCE and CARTESIAN PRODUCT.
2. Three of these operations: UNION, INTERSECTION and SET DIFFERENCE require that the tables (relations) involved be union compatible.
3. Two relations are said to be union compatible if the following conditions are satisfied:
i. The two relations/tables must contain the same number of columns (have the same degree).
ii. Each column of the first relation/table must be either the same data type as the corresponding column of the second relation/ table or convertible to the same data type as corresponding column of the second.
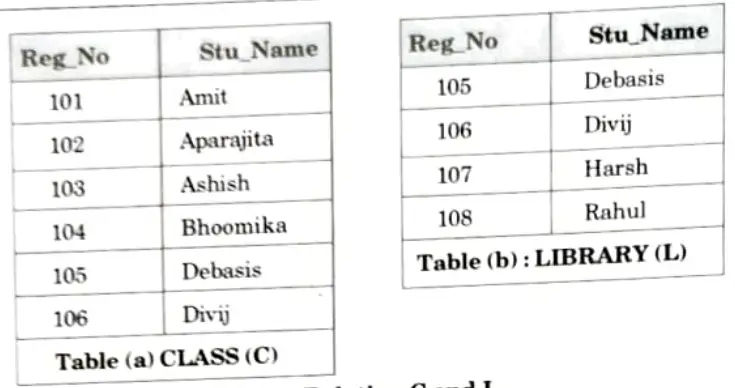
4. Now consider the two relations CLASS and LIBRARY.
5 The class and library contains the entire list of Reg_No and Stu_Name.
6. For simplicity we will call the class relation as C and the library relation as L.
7. The two relations, as we can see, are union compatible.
c. What do you understand by transitive dependencies ? Explain with an example any two problems that can arise in the database if transitive dependencies are present in the database.
Ans. A. Transitive dependencies:
- 1. A transitive dependency in a database is an indirect relationship between values in the same table that causes a functional dependency.
- 2. To achieve the normalization standard of Third Normal Form (3NF), we eliminate any transitive dependency.
- 3. A transitive dependency exists when you have the following functional dependency pattern:
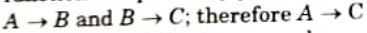
- 4. Consider the following example:
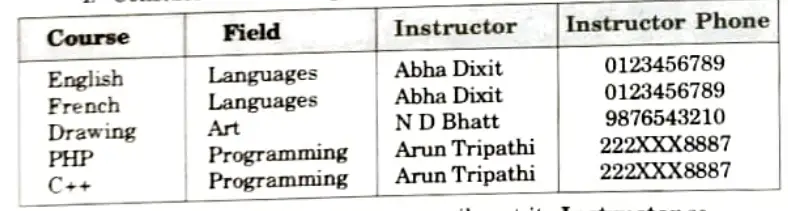
- 5. If you have a Course you can easily get its Instructor so Course → Instructor.
- 6. If you have an Instructor you can’t get his Course as he might be teaching different courses.
- 7. If you have an Instructor you can easily get his Phone so Instructor → Phone.
- 8. That means if you have a Course then you can get the Instructor Phone which means Course → Instructor Phone (i.e., Transitive dependency).
B. Transitive dependencies have following problem:
- 1. If you delete both the French and English courses then you will delete their instructor Abha Dixit as well and his phone number will be lost forever.
- 2. There is no way to add a new Instructor to your database unless you add a Course for him first or you can duplicate the data in an Instructors table which is even worse.
- 3. If Instructor Abha Dixit changes her phone number then you will have to update all Courses that she teaches with the new info which can be very prone to mistakes
- 4. You can’t delete an instructor from your database unless you delete all the courses he teaches or set all his fields to null.
d. List ACID properties of transaction. Explain the usefulness of each. What is the importance of log ?
Ans. A. ACID properties:
1. Atomicity: It implies that either all of the operations of the transaction should execute or none of them should occur.
Example: All operations in this set must be done.
If the system fails to add the amount in B’s account after deleting from A’s account, revert the operation on A’s account.
2. Consistency: The state of database before the execution of transaction and after the execution of transaction should be same.
Example: Let us consider the initial value of accounts A and B are Rs.1000 and Rs. 1500. Now, account A transfer Rs. 500 to account B.
Before transaction: A + B = 1000 + 1500 = 2500
After transaction: A + B= 500 + 2000 = 2500
Since, total amount before transaction and after transaction are same. So, this transaction preserves consistency.
3. Isolation: A transaction must not affect other transactions that are running parallel to it.
Example: Let us consider another account C. If there is any ongoing transaction between C and A, it should not make any effect on the transaction between A and B. Both the transactions should be isolated.
4. Durability: Once a transaction is completed successfully. The changes made by transaction persist in database.
Example: A system gets crashed after completion of all the operations. f the system restarts it should preserve the stable state. An amount in A and B account should be the same before and after the system gets a restart.
B. Usefulness of ACID properties:
Atomicity: Atomicity is useful to ensure that if for any reason an error occurs and the transaction is unable to complete all of its steps, then the system is returned to the state it was in before the transaction was started.
Consistency: The consistency property is useful to ensure that a complete execution of transaction from beginning to end is done without interference of other transactions.
Isolation: Isolation property is useful to ensure that a transaction should appear isolated from other transactions, even though many transactions are executing concurrently.
Durability: Durability is useful to ensure that the changes applied to the database by a committed transaction must persist in the database.
C. Importance of log:
Features of deferred database modification:
- 1. All logs written onto the database is updated when a transaction commits.
- 2. It does not require old value of data item on the log.
- 3. lt do not need extra I/O operation before commit time.
- 4 It can manage with large memory space.
- 5. Locks are held till the commit point.
Features of immediate database modification:
- 1. All logs written onto the database is updated immediately after every operation.
- 2. It requires both old and new value of data item on the log.
- 3. It needs extra I/O operation to flush out block-buffer.
- 4. It can manage with less memory space.
- 5. Locks are released after modification.
e. What do you mean by time stamping protocol for concurrency controlling ? Discuss multi version scheme of concurrency control.
Ans. Time stamping: The timestamp ordering protocol ensures that any conflicting read and write operations are executed in timestamp order. This protocol operates as follows:
- 1. Suppose that transaction Ti issues read(Q).
- a. If TS(Ti) < W-timestamp(Q), then Ti needs a value of Q that was already overwritten. Hence, read operation is rejected, and Ti is rolled back.
- b. If TS(Ti) ≥ W-timestamp (Q), then the read operation is executed, and R-timestamp (Q) is set to the maximum of R-timestamp(Q) and TS(Ti).
- 2. Suppose that transaction Ti issues write l (Q).
- a. If TS(T|) < R-timestamp(Q), then the value of Q that Ti is producing Was needed previously, and the system assumed that the value would never be produced. Hence, the system rejects write operation and rolls T back.
- b. If TS(Ti) < W-timestamp(Q), then Ti is attempting to Write an obsolete value of Q. Hence, the system rejects this write operation and rolls back Ti.
- c. Otherwise, the system executes the write operation and sets W-timestamp(Q) to TS(Ti). If a transaction Ti is rolled by the concurrency control scheme, the system assigns it a new timestamp and restarts it.
Multiversion scheme:
- 1. Multiversion concurrency control is a schemes in which each write (Q) operation creates a new version of .
- 2. When a transaction issues a read(Q) operation, the concurrency-control manager selects one of the version of Q to be read.
- 3. The concurrency control scheme must ensure that the version to be read is selected in manner that ensures serializability.
Section 3: Data Models in DBMS Long Answers
a. What are the different types of Data Models in DBMS ? Explain them.
Ans. Data models:
- 1. Data models define how the logical structure of the database is modeled.
- 2. Data models are a collection of conceptual tools for describing data, data relationships, data semantics and consistency constraints.
- 3. Data models define how data is connected to each other and how they are processed and stored inside the system.
Types of data models:
- 1. Entity relationship model:
- a. The entity relationship (ER) model consists of a collection of basic objects, called entities and of relationships among these entities.
- b. Entities are represented by means of their properties, called attributes.
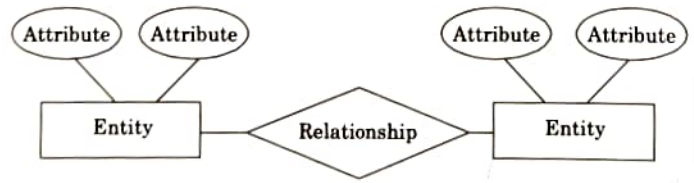
- 2. Relational model:
- a. The relational model represents data and relationships among data by a collection of tables, each of which has a number of columns with unique names.
- b. Relational data model is used for data storage and processing.
- c. This model is simple and it has all the properties and capabilities required to process data with storage efficiency.
- 3. Hierarchical model:
- a. In hierarchical model data elements are linked as an inverted tree structure (root at the top with branches formed below).
- b. Below the single root data element are subordinate elements each of which in turn has its own subordinate elements and so on, the tree can grow to multiple levels.
- c. Data element has parent child relationship as in a tree.
- 4. Network model:
- a This model is the extension of hierarchical data model.
- b. In this model there exist a parent child relationship but a child data element can have more than one parent element or no parent at all.
- 5. Object-oriented model:
- a. Object-oriented models were introduced to overcome the shortcomings of conventional models like relational, hierarchical and network model.
- b. An object-oriented database is collection of objects whose behaviour, state, and relationships are defined in accordance with object oriented concepts (such as objects, class, etc.).
b. State the procedural DML and non-procedural DML with their differences.
Ans. Procedural and non-procedural DML:
i. Procedural DMLs: It requires a user to specify what data are needed and how to get those data.
ii. Declarative DMLs (Non-procedural DMLs): It requires user to specify what data are needed without specifying how to get those data.
| S. No. | Procedural DML | Non-procedural DML |
| 1. | It is command-driven language. | It is a function-driven language |
| 2. | It works through the state of machine. | It works through the mathematical functions. |
| 3. | Its semantics are quite tough. | Its semantics are very simple. |
| 4. | It returns only restricted data types and allowed values. | It can return any data type or value. |
| 5. | Overall efficiency is very high. | Overall efficiency is low as compared to Procedural Language. |
| 6. | Size of the program written in Procedural language is large. | Size of the Non-Procedural language program is small. |
| 7. | It is not suitable for time critical applications. | It is suitable for time critical applications. |
| 8. | Iterative loops and Recursive calls both are used in the Procedural languages. | Recursive calls are used in Non-Procedural languages. |
Section 4: Database Management System Aktu Important Notes
a. Consider the following schema for institute library:
Student (RolINo, Name, Father_ Name, Branch)
Book (ISBN, Title, Author, Publisher)
Issue (RolINo, ISBN, Date-of-Issue)
Write the following queries in SQL and relational algebra:
I. List roll number and name of all students of the branch CSE
II. Find the name of student who has issued a book published by ‘ABC’ publisher.
III. List title of all books and their authors issued to a student ‘RAM’.
IV. List title of all books issued on or before December 1, 2020.
V. List al books published by publisher ‘ABC’.
Ans. 1. select Roll_No, Name from Student where Branch=”CSE”;
2. select Name
from Student
join Issue on Student. Roll_No = Issue. Roll_No
join Book on Issue.lSBN = Book.ISBN
where Publisher =”ABC”;
3. select Author, Title
from Student
join Issue on Student.Roll _No = Issue.Roll_No
join Book on Issue.ISBN = Book.ISBN
where Name =”RAM”
4. select Title
from Book
join Issue on Issue.ISBN = Book.ISBN
where date »=”2020-12-01″;
5. select Title from Book
wherePublisher =”ABC”;
b. What do you mean by trigger ? Explain it by a suitable example.
Ans. Triggers at is executed automatically:
- 1. A trigger is a procedure (code segment) when some specific events occur in a table view of a database.
- 2. Triggers are mainly used for maintaining integrity in a database. Triggers are also used for enforcing business rules, auditing changes in the database and replicating data.
Following are different types of triggers:
- 1. Data Manipulation Language (DML) triggers:
- a. DML triggers are executed when a DML operation like INSERT, UPDATE OR DELETE is fired on a Table or View.
- b. DML triggers are of two types:
- i. AFTER triggers:
- 1. AFTER triggers are executed after the DML statement completes but before it is committed to the database.
- 2. AFTER triggers if required can rollback its actions and source DML statement which invoked it.
- ii. INSTEAD OF triggers:
- 1. INSTEAD OF triggers are the triggers which get executed automatically in place of triggering DML (1.e., INSERT, UPDATE and DELETE) action.
- 2. It means if we are inserting a record and we have a INSTEAD OF trigger for INSERT then instead of INSERT whatever action is defined in the trigger that gets executed.
- 2. Data Definition Language (DDL) triggers:
- a. DDL triggers are executed when a DDL statements like CREATE, ALTER, DROP, GRANT, DENY, REVOKE, and UPDATE STATISTICS statements are executed.
- b. DDL triggers can be DATABASE scoped or SERVER scoped. The DDL triggers with server level scope gets fired in response to a DDL statement with server scope like CREATE DATABASE, CREATE LOGIN, GRANT_SERVER, ALTER DATABASE, ALTER LOGIN etc.
- c. Where as DATABASE scoped DDL triggers fire in response to DDL statement with DATABASE SCOPE like CREATE TABLE, CREATE PROCEDURE, CREATE FUNCTION, ALTER TABLE, ALTER PROCEDURE, ALTER FUNCTION etc.
- 3. LOGON triggers:
- a. LOGON triggers get executed automatically in response to a LOGON event.
- b. They get executed only after the successful authentication but before the user session is established.
- c. If authentication fails the LOGON triggers will not be fired.
- 4. CLR triggers:
- a. CLR triggers are based on the Sql CLR.
- b. We can write DML and DDL triggers by using the supported .NET CLR languages like CH, VB.NET etc.
- c. CCR triggers are useful if heavy computation is required in the trigger or a reference to object outside SQL is required.
Section 5: Armstrong’s axioms Important Quantum Notes
a. Describe Armstrong’s axioms in detail. What is the role of these rules in database development process ?
Ans. 1. The term Armstrong axioms refer to the sound and complete set of inference rules or axioms that are used to test the logical implication of functional dependencies.
2. If P is a set of functional dependencies then the closure of F, denoted as F+, is the set of all functional dependencies logically implied by F.
3. Armstrong’s axioms are a set of rules, that when applied repeatedly, generates a closure of functional dependencies.
4. Armstrong’s axioms has mainly two different sets of rules:
A. Primary Rule:

B. Secondary Rule Rule:

b. Describe the term MVD in the context of DBMS by giving an example. Discuss 4NF and 5NF also.
Ans. MVD:
1. MVD occurs when two or more independent multivalued facts about the same attribute occur within the same relation.
2. MVD is denoted by X →→Y specified on relation schema R, where X and Y are both subsets of R.
3. Both X and Y specifies the following constraint on any relation state r of R: If two tuples t1 and t2 exist in r such that t1(X) = t2(X), then two tuples t3 and t4 should also exist in r with the following properties, where we use Z to denote
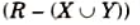
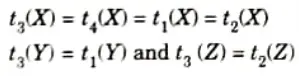
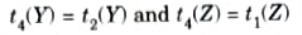
4 An MVDX → Y in R is called a trivial MVD if
a. X is a subset of Y or
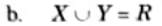
An MVD that satisfies neither (a) nor (b) is called a non-trivial MVD.
For example:
4NF and 5NF:
Fourth Normal Form (4NF):
1. A table is in 4NF, if it is in BCNF and it contains multivalued dependencies.
2 A relation schema R is in 4NF, with respect to a set of dependencies F (that includes FD and multivalued dependencies) if, for every nontrivial multivalued dependency X → → Y in F*, X is superkey for R.
For example: A Faculty has multiple courses to teach and he is leading several committees, This relation is in BCNF, since all the three attributes concatenated together constitutes its key. The rule for decomposition is to decompose the offending table into two, with the multi-determinant attribute or attributes as part of the key of both. In this case to put the relation in 4NF, two separate relations are formed as follows:

Fifth Normal Form (5NF):
1. A relation is in 5NF, if it is 4NF and cannot be further decomposed.
2. In 5NF, we use the concept of join dependency which is a generalized form of multivalued dependency.
3. A relation schema R is in 5NF or Project Join Normal Form (PJNF) with respect to a set F of functional, multivalued and join dependencies if, for every non-trivial join dependency JD (R1, R2, …….Rn) in F* (that is implied by F), every Ri is a superkey of R.
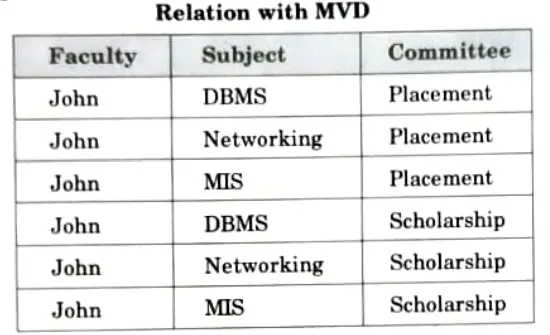
For example:
The table is in 4NF as there is no multivalued dependency.
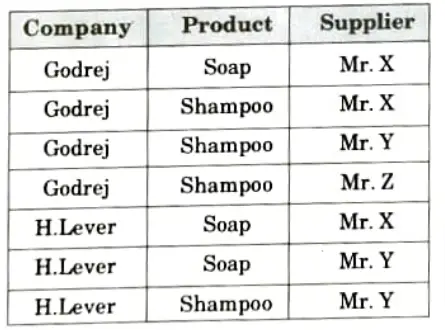
If we decompose the table then we will lose information, which can be as follows:
Suppose the table is decomposed into two parts as:
The redundancy has been eliminated but we have lost the information. NOW suppose that the original table to be decomposed in three parts, Company_Product, Company _Supplier and Product_Supplier, which is as follows:
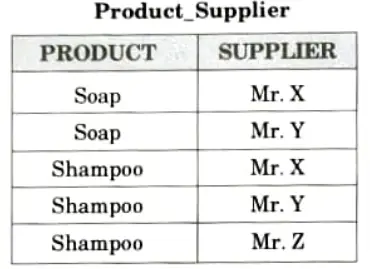
So, it is clear that if a table is in 4NF and cannot be further decomposed, it is said to be in 5NF.
Section 6: Serializable Schedule Important Questions
a. Describe serializable schedule. Discuss con flict serializability with suitable example.
Ans. Serializable schedule: Serializability is a property of a transaction schedule which is used to keep the data in the data item in consistent state. It is the classical concurrency scheme.
Serializability is required:
- 1. To control concurrent execution of transaction.
- 2. To ensure that the database state remains consistent.
Serializability of schedule:
- 1. In DBMS, the basic assumption is that each transaction preserves database consistency.
- 2. Thus, the serial execution of a set of transaction preserves database consistency.
- 3. A concurrent schedule is serializable if it is equivalent to a serial schedule.
Conflict serializability:
- 1. Consider a schedule S, in which there are two consecutive instructions Ii and Ij of transactions Ti and Tj respectively (i ≠ j).
- 2 If Ii and Ij refer to different data items, then swap Ii and Ij without affecting the results of any instruction in the schedule.
- 3. However, if Ii and Ij refer to the same data item, then the order of the two steps matter.
- 4. Following are four possible cases:
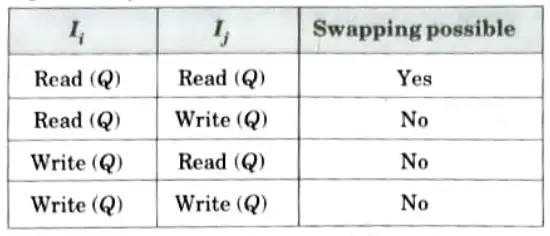
- 5. Ii and Ij conflict if there are operations by different transactions on the same dataitem, and at least one of these instructions is a write operation.
For example:
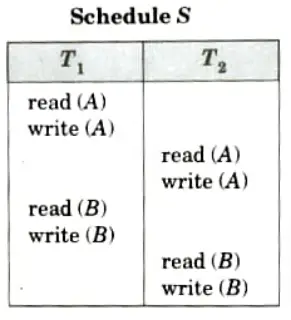
i. The write (A) instruction of T1 conflicts with read (A) instruction of T2. However, the write (A) instruction of T2 does not conflict with the read (B) instruction of T1 as they access different data items.
Schedule S’

ii. Since the write (A) instruction of T2 in Schedule S’ does not conflict with the read (B) instruction of T1 we can swap these instructions to generate an equivalent schedule.
iii. Both schedules will produce the same final system state.
6. If a schedule S can be transformed into a schedule S’ by a series of Swaps of non-conflicting instructions, we say that S and S’ are conflict equivalent.
7. The concept of conflict equivalence leads to the concept of conflict serializability and the schedule Sis conflict serializable.
b. Discuss the procedure of deadlock detection and recovery in transaction ?
Ans. Deadlock:
- 1. A deadlock is a situation in which two or more transactions are waiting for locks held by the other transaction to release the lock.
- 2. Every transaction is waiting for another transaction to finish its operations.
Methods to handle a deadlock:
- 1. Deadlock prevention protocol: This protocol ensures that the system will not go into deadlock state. There are different methods that can be used for deadlock prevention:
- a. Pre-declaration method: This method requires that each transaction locks all its data item before it starts execution.
- b. Partial ordering method: In this method, system imposes a partial ordering of all data items and requires that a transaction can lock a data item only in the order specified by partial order.
- c. Timestamp method: In this method, the data item are locked using the timestamp of transaction.
- 2. Deadlock detection:
- a. When a transaction waits indefinitely to obtain a lock, system should detect whether the transaction is involved in a deadlock or not.
- b. Wait-for-graph is one of the methods for detecting the deadlock situation.
- c. In this method a graph is drawn based on the transaction and their lock on the resource.
- d. If the graph created has a closed loop or a cycle, then there is a deadlock.
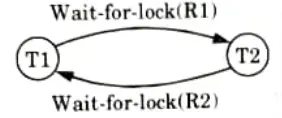
- 3. Recovery from deadlock:
- a. Selection of a victim: In this we determine which transaction (or transactions) to roll back to break the deadlock. We should rollback those transactions that will incur the minimum cost.
- b. Rollback: The simplest solution is a “total rollback”. Abort the transaction and then restart it.
- c. Starvation: In a system where selection of transactions, for rollback, is based on the cost factor, it may happen that the some transactions are always picked up.
- 4. Deadlock avoidance: Deadlock can be avoided by following methods:
- a. Serial access: If only one transaction can access the database at a time, then we can avoid deadlock.
- b. Autocommit transaction: It includes that each transaction can only lock one resource immediately as it uses it, then finishes its transaction and releases its lock before requesting any other resource.
- c. Ordered updates: If transactions always request resources in the same order (for example, numerically ascending by the index value of the row being locked) then system do not enters in deadlock state.
- d. By rolling back conflicting transactions.
- e. By allocating the locks where needed.
Section 7: database Management System Repeated Questions
a. Given a schedule S for transactions T1 and T2 with set of read and write operations,
S: R1(X) R2(X) R2(Y W2(Y) RI(Y) W1(X).
Identify, whether given schedule is equivalent to serial schedule or not ?
Ans. Schedule S

This schedule is conflict serializable. The schedule is conflict equivalent to T2T1.
b. Discuss 2 phase commit (2PC) protocol and time stamp based protocol with suitable example. How the validation based protocols differ from 2PC?
Ans. Two phase commit:
- 1. Two-phase commit (2PC) is a standardized protocol that ensures atomicity, consistency, isolation and durability (ACID) of a transaction; it is an atomic commitment protocol for distributed systems.
- 2. In a distributed system, transactions involve altering data on multiple databases or resource managers, causing the processing to be more complicated since the database has to coordinate the committing or rolling back of changes in a transaction as a self contained unit; either the entire transaction commits or the entire transaction rolls back.
Time stamp based protocol: Timestamp based protocol ensures serializability. It selects an ordering among transactions in advance using timestamps.
Difference:
| S. No. | 2PC | Validation Based Protocol |
| 1. | The 2PC protocol is a blocking Two-Phase commit protocol. | The validation based protocol (3PC) is a non-blocking Three-Phase commit protocol. |
| 2. | For 2PC, the coordinator may abort the transaction globally or resend the global decision. | For 3PC, the coordinator can abort the transaction globally, send global-commit message to the participants or simply send the global decision to all sites that have not acknowledged. |
6 thoughts on “Database Management System: Aktu Solved Previous Question Paper Quantum Notes”