
With the B.Tech AKTU Quantum Book, you may delve into the complexities of Compiler Design. Access key notes, frequently asked questions, and helpful insights to help you learn this critical area. Unit-1 Introduction to Compiler
Dudes 🤔.. You want more useful details regarding this subject. Please keep in mind this as well. Important Questions For Compiler Design: *Quantum *B.tech-Syllabus *Circulars *B.tech AKTU RESULT * Btech 3rd Year * Aktu Solved Question Paper
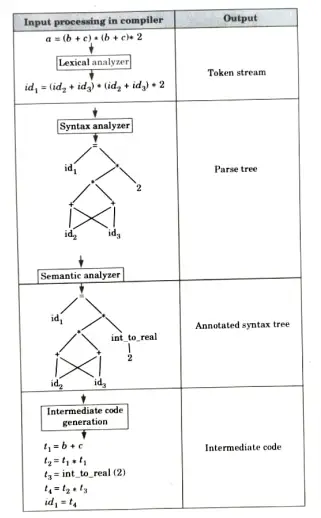
Q1. Explain in detail the process of compilation. Illustrate the output of each phase of compilation of the input
“a (b+c)*(b + c)* 2″.
Ans. A compiler contains 6 phases which are as follows:
i. Phase 1 (Lexical analyzer):
- a. The lexical analyzer is also called scanner.
- b. The lexical analyzer phase takes source program as an input and separates characters of source language into groups of strings called token.
- c. These tokens may be keywords identifiers, operator symbols and punctuation symbols.
ii. Phase 2 (Syntax analyzer):
- a. The syntax analyzer phase is also called parsing phase.
- b. The syntax analyzer groups tokens together into syntactic structures.
- c. The output of this phase is parse tree.
iii. Phase 3 (Semantic analyzer):
- a. The semantic analyzer phase checks the source program for semantic errors and gathers type information for subsequent code generation phase.
- b. It uses parse tree and symbol table to check whether the given program is semantically consistent with language definition.
- c. The output of this phase is annotated syntax tree.
iv. Phase 4 (Intermediate code generation):
- a. The intermediate code generation takes syntax tree as an input from semantic phase and generates intermediate code.
- b. It generates variety of code such as three address code, quadruple, triple.
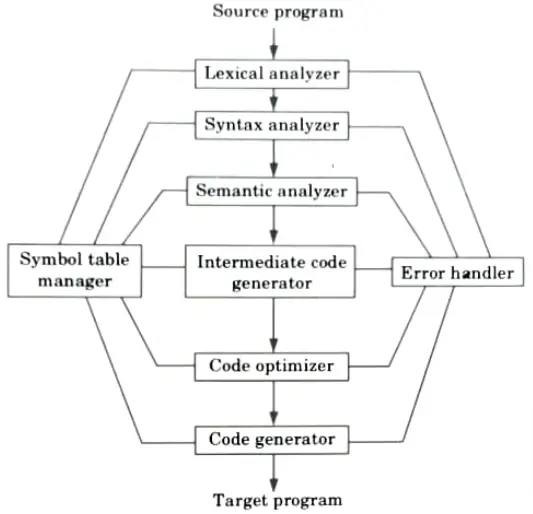
v. Phase 5 (Code optimization): This phase is designed to improve the intermediate code so that the ultimate object program runs faster and takes less space.
vi. Phase 6 (Code generation):
- a. It is the final phase for compiler.
- b. It generates the assembly code as target language.
- c. In this phase, the address in the binary code is translated from logical address.
Symbol table/ table management: A symbol table is a data structure containing a record that allows us to find the record for each identifier quickly and to store or retrieve data from that record quickly.
Error handler: The error handler is invoked when a flaw in the source program is detected.
Compilation of “a (b+c)*(b + c)* 2″:

Q2. What are the types of passes in compiler ?
Ans. Types of passes:
- 1. Single-pass compiler:
- a. When a line source is processed by a single-pass compiler, it is scanned and the tokens are extracted.
- b. Next, the tree structure and several tables providing details about each token are generated after the grammar of the line has been examined.
- 2. Multi-pass compiler: In a multi-pass compiler, the input source is scanned once to create the first modified form, which is then followed by another scan to create a second modified form, and so on, until the object form is created.
Q3. Discuss the role of compiler writing tools. Describe various compiler writing tools.
Ans. Role of compiler writing tools:
- 1. Compiler writing tools are used for automatic design of compiler component.
- 2. Every tool uses specialized language.
- 3. Writing tools are used as debuggers, version manager.
Various compiler construction/writing tools are:
- 1. Parser generator: The procedure produces syntax analyzer, normally from input that is based on context free grammar.
- 2. Scanner generator: It automatically generates lexical analyzer, normally from specification based on regular expressions.
- 3. Syntax directed translation engine:
- a. It produces collection of routines that are used in parse tree.
- b. These translations are associated with each node of parse tree, and each translation is defined in terms of translations at its neighbour nodes in the tree.
- 4. Automatic code generator: These tools take a collection of rules that define translation of each operation of the intermediate language into the machine language for target machine.
- 5. Data flow engine: The data flow engine is use to optimize the code involved and gathers the information about how values are transmitted from one part of the program to another.
Q4. How does finite automata useful for lexical analysis ?
Ans.
- 1. Lexical analysis is the process of reading the source text of a program and converting it into a sequence of tokens.
- 2. The lexical structure of every programming language can be specified by a regular language, a common way to implement a lexical analyzer is to:
- a. Specify regular expressions for all of the kinds of tokens in the language.
- b. The disjunction of all of the regular expressions thus describes any possible token in the language.
- c. Convert the overall regular expression specifying all possible tokens into a Deterministic Finite Automaton (DFA).
- d Translate the DFA into a program that simulates the DFA. This program is the lexical analyzer.
- 3. This approach is so useful that programs called lexical analyzer generators exist to automate the entire process.
Q5. Explain the implementation of lexical analyzer.
Ans. Lexical analyzer can be implemented in following step:
- 1. Input to the lexical analyzer is a source program.
- 2. By using input buffering scheme, it scans the source program.
- 3. Regular expressions are used to represent the input patterns.
- 4. Now this input pattern is converted into NFA by using finite automation machine.
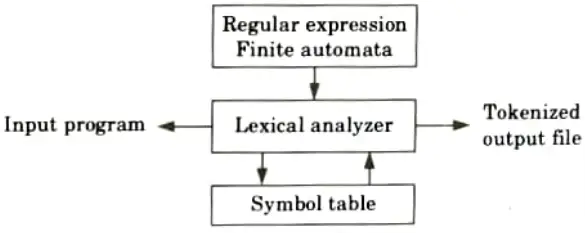
- 5. This NFA is then transformed into DFA, and DFA is minimised using various reduction techniques.
- 6. The pattern is recognised using the reduced DFA that has been divided into lexemes.
- 7. A programming language phase that evaluates the words that match the regular expression is connected to each minimised DFA.
- 8. The tool then builds programme code that comprises the state table, the evaluation phases, and a function that uses them appropriately, together with a state table for the relevant finite state machine.
Q6. Explain different parts of LEX program.
Ans. The LEX program consists of three parts:

1. Declaration section:
- a. In the declaration section, declaration of variable constants can be done.
- b. Some regular definitions can also be written in this section.
- c. The regular definitions are basically components of regular expressions.
2. Rule section:
- a. The rule section consists of regular expressions with associated actions. These translation rules can be given in the form as:

Where each Ri is a regular expression and each action, is a program fragment describing what action is to be taken for corresponding regular expression.
- b. These actions can be specified by piece of C code.
3. Auxiliary procedure section:
- a. In this section, all the procedures are defined which are required by the actions in the rule section.
- b. This section consists of two functions:
- i. main() function
- ii. yywrap() function

Compiler Design Btech Quantum PDF, Syllabus, Important Questions
| Label | Link |
|---|---|
| Subject Syllabus | Syllabus |
| Short Questions | Short-question |
| Question paper – 2021-22 | 2021-22 |
Compiler Design Quantum PDF | AKTU Quantum PDF:
| Quantum Series | Links |
| Quantum -2022-23 | 2022-23 |
AKTU Important Links | Btech Syllabus
| Link Name | Links |
|---|---|
| Btech AKTU Circulars | Links |
| Btech AKTU Syllabus | Links |
| Btech AKTU Student Dashboard | Student Dashboard |
| AKTU RESULT (One VIew) | Student Result |