
Providing B.Tech. (Sem. 3rd) Odd Semester Theory Examination, 2021-22 Data Structures Question Paper with Solution. Prepare for your AKTU B.Tech Data Structures exam with the latest question paper from 2021-2022.
Dudes 🤔.. You want more useful details regarding this subject. Please keep in mind this as well. Important Questions For Data Structures : *Unit-01 *Unit-02 *Unit-03 *Unit-04 *Unit-05 *Short-Q/Ans *Question-Paper with solution 21-22
Section A : Short Questions
a. Convert the infix expression (A+B) *(C-D) $ E*F to postfix. Give the answer without any spaces.
Ans.

b. Rank the following typical bounds in increasing order of growth rate: O(log n), O(n4), O(1), O(n2log n).
Ans. O(1) < O(log n) < O(n2log n) < O(n4)
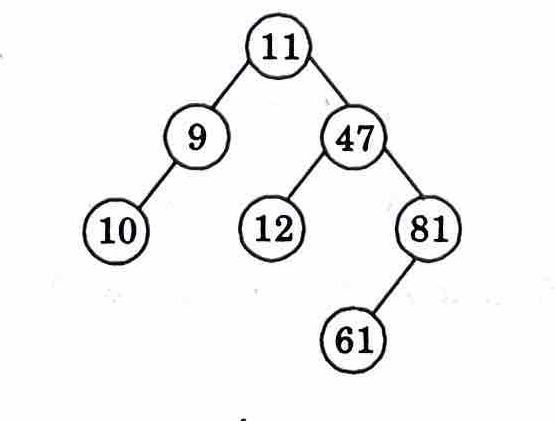
c. Draw the binary search tree that results from inserting the following numbers in sequence starting with 11 : 11, 47, 81, 9, 61, 10, 12
Ans. 11, 47, 81, 9, 61, 10, 12
d. What does the following recursive function do for a given Linked list with first node as head ?
void fun 1 (struct node* head)
{
if(head = NULL)
Return;
Fun 1 (head->next);
printf(“%d”, head ->data);
}
Ans. The function prints all nodes of linked list in reverse order. fun1() prints the given Linked List in reverse manner. For Linked List 1 ->2 ->3 ->4 ->5, fun1() prints 5-> 4 ->3 ->2 ->1.
e. Define a sparse matrix. Suggest a space-efficient representation for space matrices.
Ans. 1. Sparse matrices are the matrices in which most of the elements of the matrix have zero value.
2. Two general types of n-square sparse matrices, which occur in various applications, as shown in Fig..
3. It is sometimes customary to omit block of zeros in a matrix as in Fig. . The first matrix, where all entries above the main diagonal are zero or, equivalently, where non-zero entries can only occur on or below the main diagonal, is called a lower triangular matrix.
4. The second matrix, where non-zero entries can only occur on the diagonal or on elements immediately above or below the diagonal, is called tridiagonal matrix.

There are two ways of representing sparse matrices:
1. Array representation:
i. In the array representation of a sparse matrix, only the non-zero elements are stored so that storage space can be reduced.
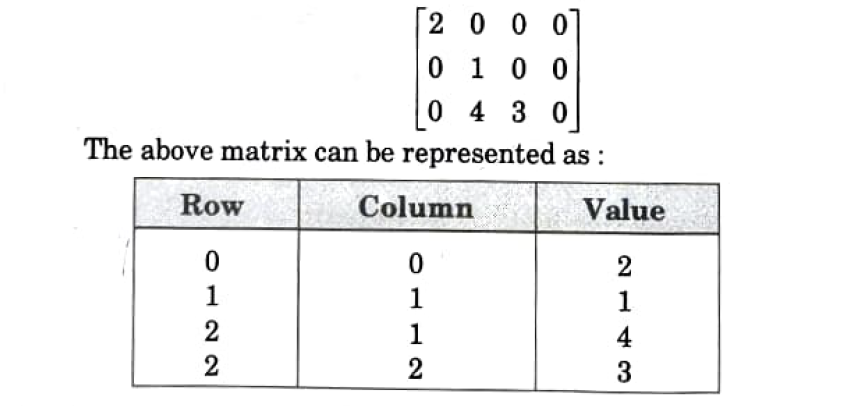
ii. Each non-zero element in the sparse matrix is represented as (row, column, value).
.
iii. For this a two-dimensional array containing three columns can be used. The first column is for storing the row numbers, the second column is for storing the column numbers and the third column represents the value corresponding to the non-zero element at (row, column) in the first two columns.
iv. For example, consider the following sparse matrix:
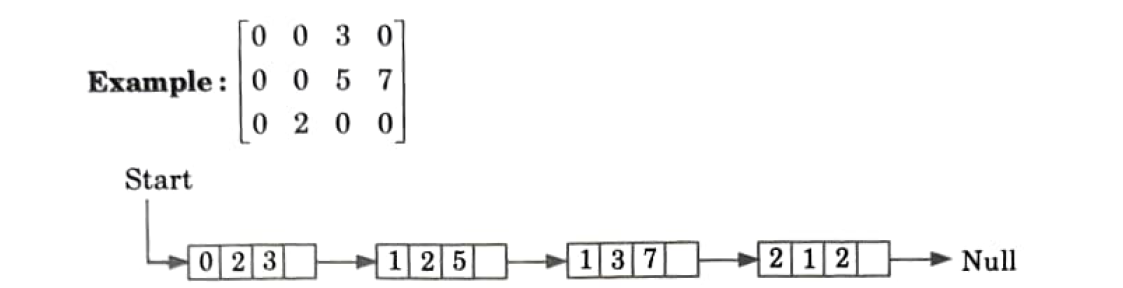
2. Linked representation:
In the linked list representation each node has four fields. These four fields are defined as
a. Row: Index of row, where non-zero element is located.
b. Column: Index of column, where non-zero element is located.
c. Value: Value of non-zero element located at index (row, column).
d Next node: Address of next node.

f. List the advantages of a doubly linked list over single linked list.
Ans. Following are the advantages of a doubly linked list over the single linked list:
- 1. It allows us to iterate in both directions.
- 2. We can delete a node easily as we have access to its previous node.
- 3. Reversing is easy.
- 4. It can grow or shrink in size dynamically.
- 5. Useful in implementing various other data structures.
g. Give an example of one of each stable and unstable sorting technique.
Ans. Examples of stable algorithm are Merge Sort, Insertion Sort, Bubble Sort, and Binary Tree Sort, Quick Sort, Heap Sort, and Selection Sort are the unstable sorting algorithm.
h. Write advantages of AVL tree over Binary Search Tree (BST).
Ans. Advantages of AVL free over binary search tree are:
- 1. The height of the AVL tree is always balanced.
- 2. The height never grows beyond log N, where N is the total number of nodes in the tree.
- 3. It gives better search time complexity when compared to simple Binary Search trees.
- 4. AVL trees have self-balancing capabilities.
i. What is tail recursion? Explain with a suitable example.
Ans. Tail recursion:
1. Tail recursion (or tail-end recursion) is a special case of recursion in which the last operation of the function, the tail call is a recursive call. Such recursions can be easily transformed to iterations.
2. Replacing recursion with iteration, manually or automatically, can drastically decrease the amount of stack space used and improve efficiency.
3. Converting a call to a branch or jump in such a case is called a tail call optimization.
For example:
Consider this recursive definition of the factorial function in C:
factorial (n)
{
if n== 0)
return 1;
return n * factorial (n- 1);
}
4. This definition is tail recursive since the recursive call to factorial is not the last thing in the function (its result has to be multiplied by
n).
factorial (n, accumulator)
{
if(n== 0)
return accumulator;
return factorial (n -1, n * accumulator);
}
factorial (n)
{
return factorial (n -1);
}
j. Write different representations of graphs in the memory.
Ans. Two types of graph representation are as follows:
1. Matrix representation: Matrices are commonly used to represent graphs for computer processing. Advantages of representing the graph in matrix lies on the fact that many results of matrix algebra can be readily applied to study the structural properties of graph from an
algebraic point of view.



Section – B : Long Questions
a. Write the advantages and disadvantages of linked lists over arrays. Write a C function creating a new linear linked list by selecting alternate elements of a linear linked list.
Ans. Advantages:
- 1 Linked lists are dynamic data structures as it can grow or shrink during the execution of a program.
- 2. The size is not fixed.
- 3. Data can store non-continuous memory blocks.
- 4. Insertion and deletion of nodes are easier and efficient. Unlike array a linked list provides flexibility in inserting a node at any specified position and a node can be deleted from any position in the linked list.
- 5. Many more complex applications can be easily carried out with linked lists.
Disadvantages:
1. More memory : In the linked list, there is a special field called link field which holds address of the next node, so linked list requires extra space.
2. Accessing to arbitrary data item is complicated and time consuming task.



b. Write the algorithm of insertion sort, Implement the same on the following numbers; also calculate its time complexity. 13, 16, 10, 11, 4, 12, 6, 7.
Ans.



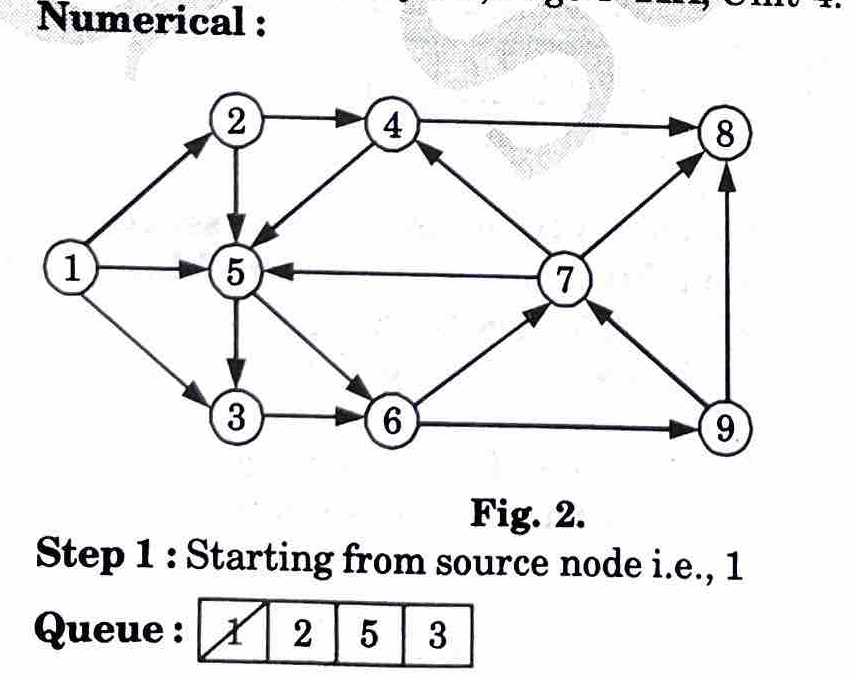
c. Differentiate between DFS and BFS. Draw the breadth First Tree for the above graph.

Ans. Difference:
Various types of traversing techniques are:
1. Breadth First Search (BFS) 2. Depth First Search (DFS)
Importance of BFS:
1. It is one of the single source shortest path algorithms, so it is used to compute the shortest path.
2. It is also used to solve puzzles such as the Rubik’s Cube.
3. BFS is not only the quickest way of solving the Rubik’s Cube, but also the most optimal way of solving it.
Application of BFS : Breadth first search can be used to solve many problems in graph theory, for example:
1. Copying garbage collection.
2. Finding the shortest path between two nodes u and u, with path length measured by number of edges (an advantage over depth first search).
3. Ford-Fulkerson method for computing the maximum flow in a flow network.
4. Serialization/Deserialization of a binary tree vs serialization in sorted order, allows the tree to be re-constructed in an efficient manner.
5. Construction of the failure function of the Aho-Corasick pattern matcher.
6. Testing bipartiteness of a graph.
Importance of DFS: DFS is very important algorithm as based upon DFS,
there are O(V + E)-time algorithms for the following problems
1. Testing whether graph is connected.
2. Computing a spanning forest of G.
3.Computing the connected components of G.
4. Computinga path between two vertices of G or reporting that no such path exists.
5. Computing a cycle in G or reporting that no such cycle exists.
Application of DFS: Algorithms that use depth first search as a building block include
1. Finding connected components.
2 Topological sorting.
3. Finding 2-(edge or vertex)-connected components.
4. Finding 3-(edge or vertex)-connected components.
5. Finding the bridges of a graph.
6. Generating words in order to plot the limit set of a group.
7. Finding strongly connected components.

d. Differentiate between linear and binary search algorithms. Write a recursive function to implement binary search.
Ans.
| S. No. | Sequential (linear) search | Binary search |
| 1. | No elementary condition i.e., array can be sorted or unsorted. | Elementary condition i.e., array should be sorted. |
| 2. | It takes long time to search an element. | It takes less time to search an element. |
| 3. | Complexity is O(n). | Complexity is O(log2 n). |
| 4. | It searches data linearly. | It is based on divide andconquer method. |
Binary search (A, n, item, loc)
Let A is an array of ‘n’ number of items, item is value to be searched.
1. Set: beg ≤ 0, Set: end = n – 1, Set: mid = (beg + end)/2
2. While ((beg s end) and (a [mid] != item)
3. If (item < almid])
then Set: end = mid-1
else
Set: beg = mid + 1
endif
Set: mid = (beg + end) /2
endwhile
5. If (beg > end) then
4. Set loc = -1 /element not found
else
Set: loc = mid
endif
6. Exit
Analysis of binary search:
The complexity of binary search is O(log2 n).
e. What is the significance of maintaining threads in Binary Search Tree? Write an algorithm to insert a node in thread binary tree.
Ans. Significance:
1. In threaded binary tree the traversal operations are very fast.
2. In thre aded binary tree, we do not require stack to determine the predecessor and successor node.
3. In a threaded binary tree, one can move in any direction i.e., upward or downward because nodes are circularly linked.
4. Insertion into and deletions from a threaded tree are all although time consuming operations but these are very easy to implement.
Algorithm for inorder traversal in threaded binary tree:
1. Initialize current as root
2. While current is not NULL
If current does not have left child
a. Print current’s data
b. Go to the right, i.e., current = current->right
Else
a. Make current as right child of the rightmost node in current’s left subtree
b. Go to this left child, i.e., current = current -> left
Section – C
a. Suppose a three-dimensional array A is declared using A[1:10,-5:5,-10:5]
i. Find the length of each dimension and the number of elements in A.
ii. Explain row major order and column major order in detail with explanation formula expression.
Ans. i. Length of each dimension and the number of elements in A:
1. The length of a dimension is obtained by: Length = Upper Bound – Lower bound + 1
2. Hence, the lengths of the dimension of A are:
L1 = 10 – 1 +1 = 10
L2 = 5 – (-5) + 1 =11
L3 = 5 – (-10) + 1 = 16
3. Therefore, A has 10 x 11 x 16 = 1760 elements
ii. A. Row major order :
1. In row major order, the element of an array is stored in computer memory as row-by-row.
2. Under row major representation, the first row of the array occupies the first set of memory locations reserved for the array, the second row Occupies the next set, and so forth.
3. In row major order, elements of a two-dimensional array are ordered as:

a. Move the elements of the second row starting from the first element to the memory location adjacent to the last element of the first row.
b. When this step is applied to all the rows except for the first row, we have a single row of elements. This is the row’s major representation.
c. By application of above-mentioned process, we get
{a, b, c, d,e, f.8, h, i,j, k, }
B. Column major order:
1. In column-major order the elements of an array is stored as column-by column,
it is called column-major order.
2. Under column major representation, the first column of the array occupies the first set of memory locations reserved for the array, the second column occupies the next set, and so forth.
3. In column major order, elements are ordered as:

a. Transpose the elements of the array. Then, the representation will be same as that of the row majör representation.
b. Then perform the process of row-major representation.
c. By application of above mentioned process, we get
{a, e, i, b,f.j., c, g, k, d, h, 1}.
C. Formula expression for 3-D array:
In three-dimensional array, address is calculated using following two
methods:
Row major order:
Location (Ali, j, k)) = Base (A) + mn (k – 1) +n (i-1) +-1)
Column major order:
Location (Ali, j, è] ) = Base (A) + mn (k-1)+ m j-1)+ (i-1)
For example: Given an array [1.8, 1.5, 1.7] of integers. If Base (A) = 900
then address of element A[5, 3, 6], by using rows and columns methods are:
The dimensions of A are: M= 8, N= 5, R = 7, i = 5,j =3, k* 6
Row major order:
Location (A [i,j, E)) = Base (A) + mn (k -1)+n (i -1) + j-1)
Location (A[5, 3, 6]) = 900 +8 x 5(6-1) + 5(5-1) + (3-1)
= 900 +40×5+5×4+2
= 900+200+20+2 = 1122
Column major order:
Location (A[i, j, k]) = Base (A) + mn (k-1) + m (j -1) + (i -1)
Location (A[5, 3, 6]) = 900+8x 5(6-1)+8(3-1)+ (5-1)
=900+ 40×5+8 x2+4
=900+ 200 +16+4 1120
b. Discuss the representation of polynomials of a single variable using a linked list. Write ‘C’ functions to add two such polynomials represented by a linked list.
Ans. Representation of polynomial:
1. In the linked representation of polynomials, each node should consist of
three elements, namely coefficient, exponent, and a link to the next term.
2. The coefficient field holds the value of the coefficient of a term, the exponent field contains the exponent value of that term and the link field contains the address of the next term in the polynomial.

3. The link coming out of the last node is NULL pointer. In case of polynomial of 3 variables i.e., X,y, 2 can also be represented as linked list as shown in Fig. 1.44.3.

Function:
Let p and q be the two polynomials represented by the linked list.
1. While p and q are not null, repeat step
2. If powers of the two terms are equal then,
if the terms do not cancel then insert the sum of the terms into the sum
(resultant)
Polynomial
Update p
Update q
Else if the (power of the first polynomial)> (power of second polynomial) Then insert the term from first polynomial into sum polynomial
Update p
Else insert the term from second polynomial into sum polynomial
Update q
3. Copy the remaining terms from the non-empty polynomial into the sum
polynomial.

Section 4
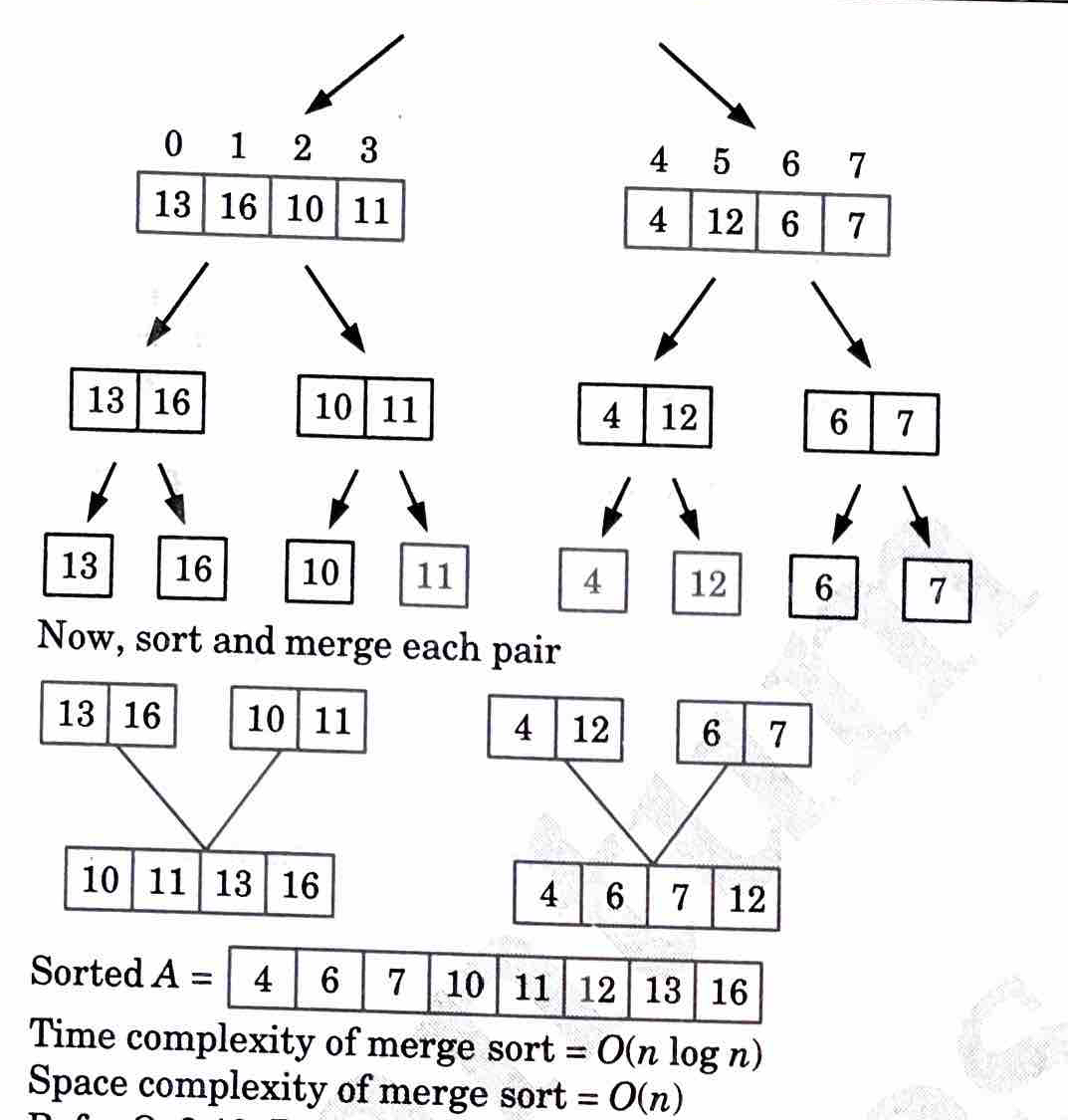
a. i. Use the merge sort algorithm to sort the following elements in ascending order.
13, 16, 10, 11, 4, 12, 6, 7.
What is the time and space complexity of merge sort?
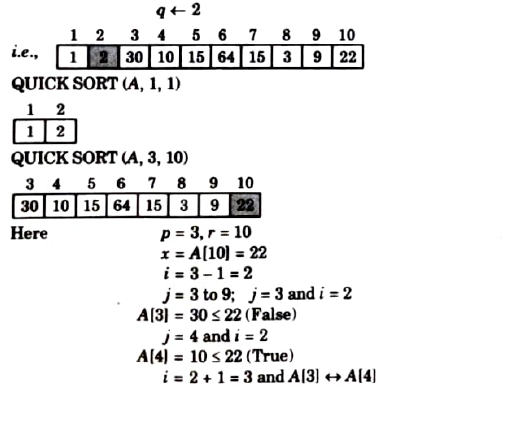
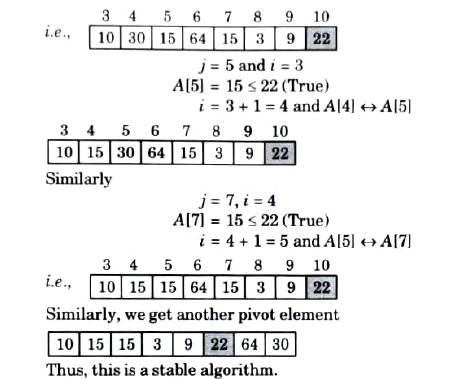
ii. Use quick sort algorithm to sort 15, 22, 30, 10, 15, 64, 1, 3, 9, 2.
Is it a stable sorting algorithm? Justify.
Ans.



b. i. The keys 12, 17, 13, 2, 5, 43, 5, and 15 are inserted into an initially empty hash table of length 15 using open addressing with hash function h (k) = k mod 10 and linear probing. What is the resultant hash table?
ii. Differentiate between linear and quadratic probing techniques.
Ans.

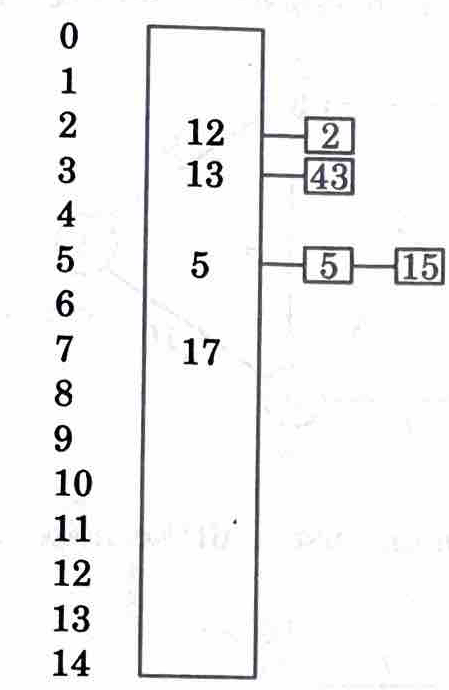
ii.

5. Attempt any one part of the following: (10 x 1 = 10)
5 a. Use Dijkstra’s algorithm to find the shortest paths from source to all other vertices in the following graph.
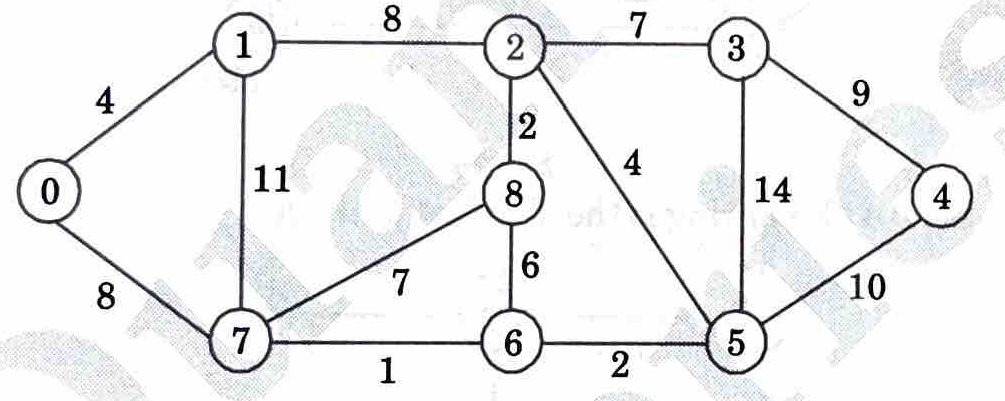
Ans. Step 1: Assign cost to vertices considering a as the source node.
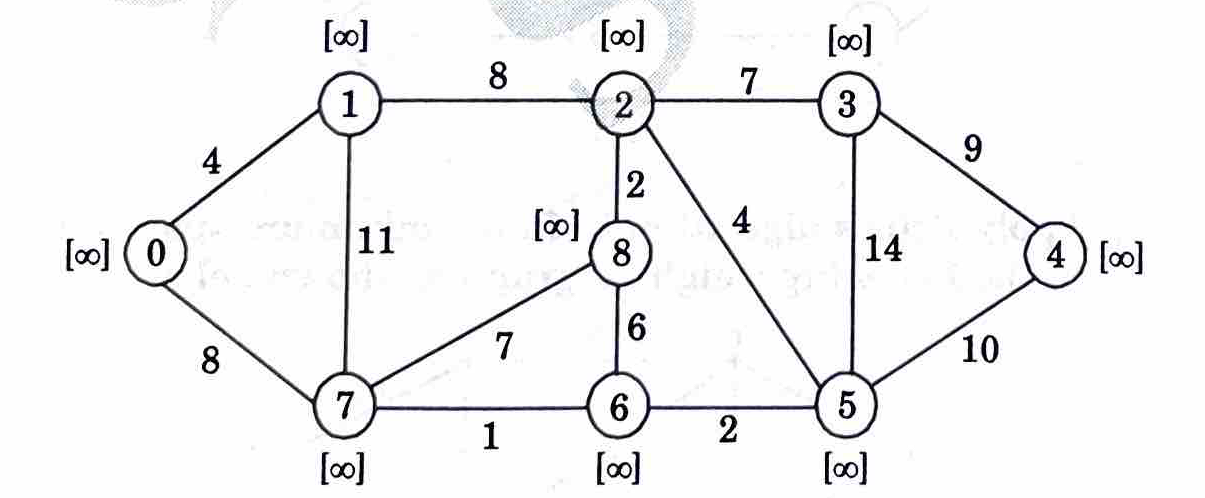
Step 2: Calculate minimum cost for neighbors of selected source.

Step 3: Similarly calculate minimum cost of all the nodes as
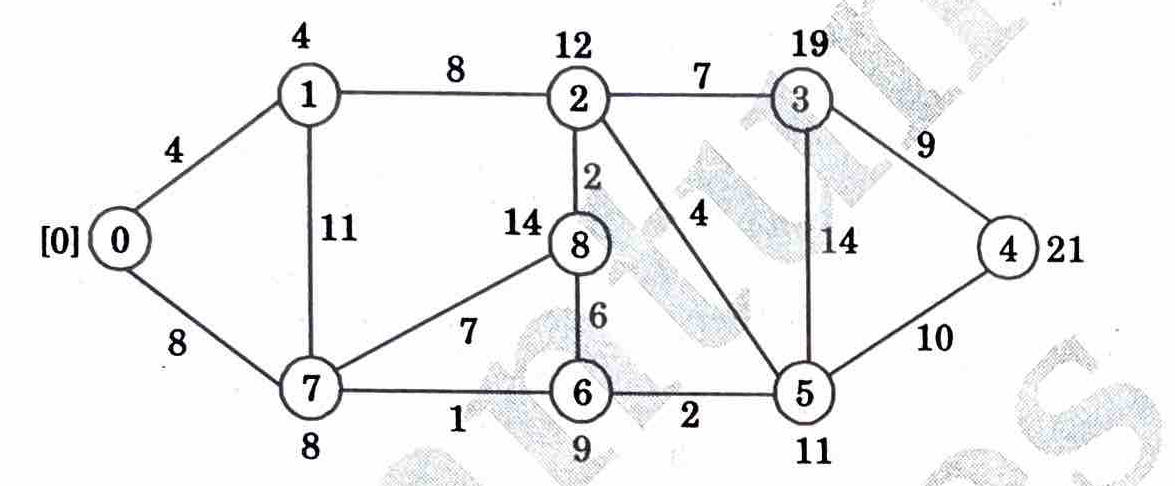
Step 4: Following is the shortest path tree.
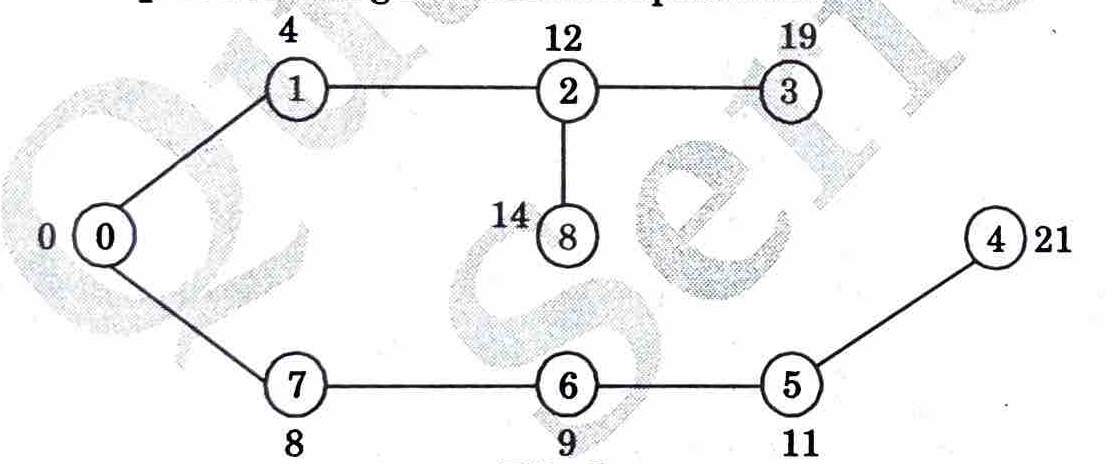
b. Apply Prim’s algorithm to find a minimum spanning tree in the following weighted graph as shown below.

Ans.
6. Attempt any one part of the following: (10 x 1 = 10)
a. i. Write an iterative function to search a key in Binary Search Tree (BST).
ii. Discuss the disadvantages of recursion with some suitable examples.
Ans. i. FINDINFO, LEFT, RIGHT, ROOT, ITEM, LOC, PAR)
A binary search tree Tis the memory and an ITEM of information is given. This procedure finds the location LOC of ITEM in T and also the location PAR of the parent of ITEM. There are three special cases:
i. LOC = NULL and PAR = NULL will indicate that the tree is empty.
ii. LOC ≠ NULL and PAR = NULL will indicate that ITEM is the root of T.
ii. LOC = NULL and PAR ≠ NULL will indicate that ITEM is not in T and
can be added to T as a child of the node N with location PAR.
1. [Tree empty ?]
If ROOT = NULL, then: Set LOC := NULL and PAR := NULL, and Return.
2. [ITEM at root ?]
If ITEM = INFO[ROOT], then: Set LOC:= R00T and PAR := NULL, and Return.
3. Initialize pointers PTR and SAVE.]
If ITEM < INFO[ROOT], then:
Set PTR: LEFT|ROOT) and SAVE:= ROOT.
Else
Set PTR:= RIGHT|ROOT) and SAVE := ROOT.
End of If structure.
4. Repeat steps 5 and 6 while PTR # NULL:
5. [ITEM found ?]
If ITEM = INFO[PTR], then: Set LOC = PTR and PAR := SAVE, and
Return.
6. If ITEM< INFO[PTR], then:
Set SAVE:s PTR and PTR:= LEFT[PTR].
Else:
Set SAVE:= PTR and PTR:= RIGHT[PTR].
[End of If structure]
[End of step 4 loop. Search unsuccessful.]
7. Set LOC= NULL and PAR = SAVE.
8. Exit.
ii. Following are the disadvantages of recursion:
1. Recursive functions are generally slower than non-recursive function.
2. It may require a lot of memory space to hold intermediate results on the system stacks.
3. Hard to analyze or understand the code.
4. It is not efficient in terms of space and time complexity.
5. The computer may run out of memory if the recursive calls are not properly checked.
b. i. What is Recursion?
ii. Write a C program to calculate factorial of number using recursive and non-recursive functions.
Ans. i. Recursion:
1. Recursion is a process of expressing a function that calls itself to perform specific operation.
2. Indirect recursion occurs when one function calls another function that then calls the first function.
3. Suppose P is a procedure containing either a call statement to itself or a call statement to a second procedure that may eventually result in a call statement back to the original procedure P.
4. Then Pis called recursive procedure. So the program will not continue to run indefinitely.
5. A recursive procedure must have the following two properties:
a. There must be certain criteria, called base criteria, for which procedure does not call itself. the
b. Each time the procedure does call itself, it must be closer to the criteria.
6. A recursive procedure with these two properties is said to be well- defined.
7. Similarly, a function is said to be recursively defined if the function definition refers to itself.
8. Again, in order for the definition not to be circular, it must have the following two properties:
a. There must be certain arguments, called base values, for which the function does not refer to itself.
b. Each time the function does refer to itself, the argument of the function must be closer to a base value.
ii. Program:
#include <stdio.h>
#include<conio.h>
void main()
{
int n, a, b;
clrscr();
printf(“Enter any number \n”);
scanf(“%d”, &n);
a= recfactorial(n);
printf(“The factorial of a given number using recursion is %d\n”, a);
b= nonrecfactorial(n);
printf(“The factorial of a given number using nonrecursion is %d”, b);
getch();
}
int recfactorial(int x)
{
int f;
if(x == 0)
{
return(1);
}
Else
{
f=x * recfactorial(x – 1);
return(f);
}
}
int nonrecfactorial(int x)
{
int i, f= 1;
for(i = 1; i<= x; i++)
{
f= f*i;
}
return(f);
}
7. Attempt any one part of the following: (10 x 1 = 10)
a. i. Why does time complexity of search operation in B-Tree is better than Binary Search Tree (BST)?
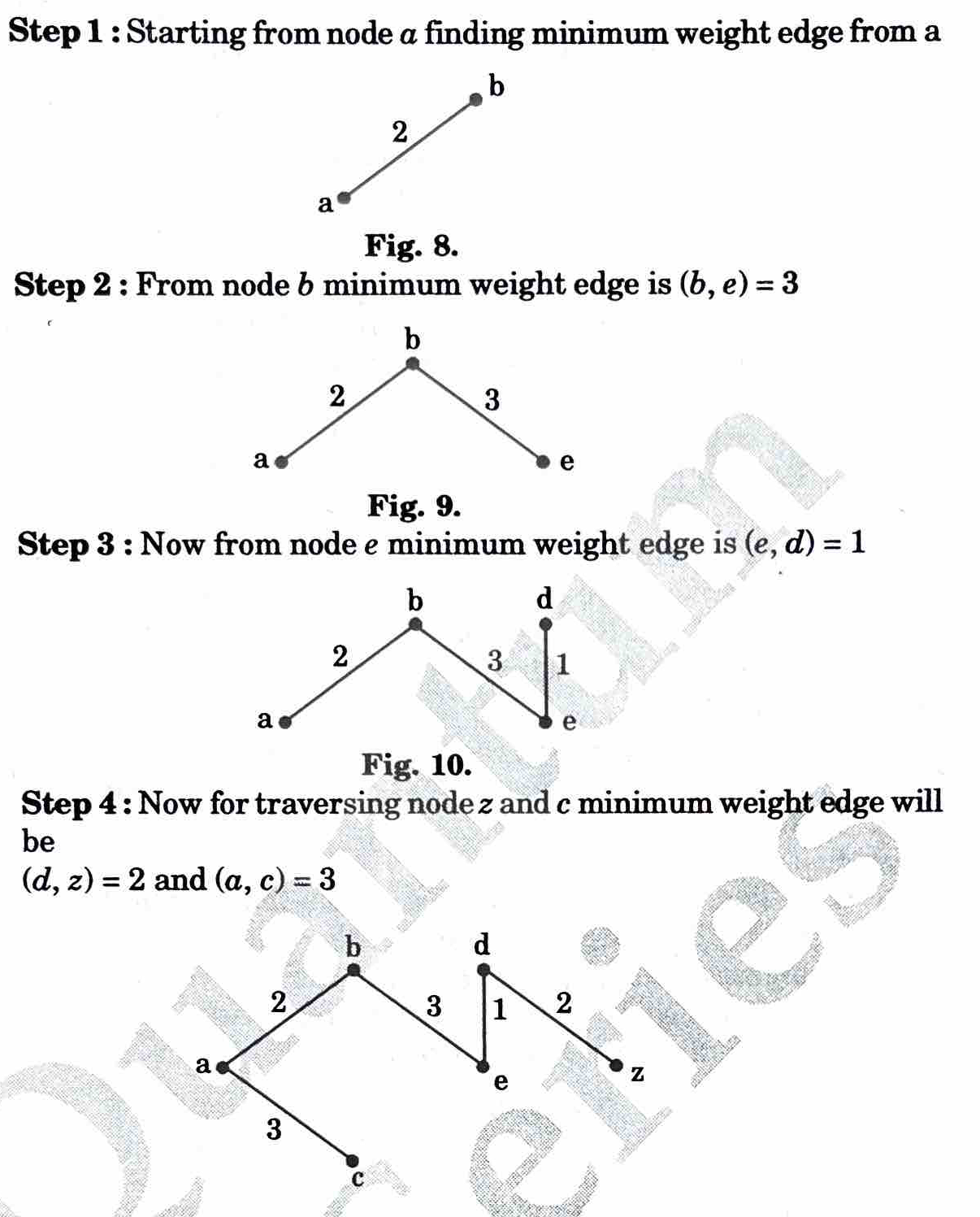
ii. Insert the following keys into an initially empty B-tree of order 5
a, g, f, b, k, d, h, m, j, e, s, i, r, x, c, l, n, t, u, p
iii. What will be the resultant B-Tree after deleting keys j, t and d in sequence?
Ans. i. D-Tree and BST are the types of non-linear data structure. Use of B-Tree instead of BST significantly reduces access time because of high branching factor and reduced height of the tree , as B-Tree is a self balancing tree and it has height log, n where is the order of the tree and n is number of nodes.
ii. a, g, f, b, k, d, h, m, j, e, s, i, r, x, c, l, n, t, u, p
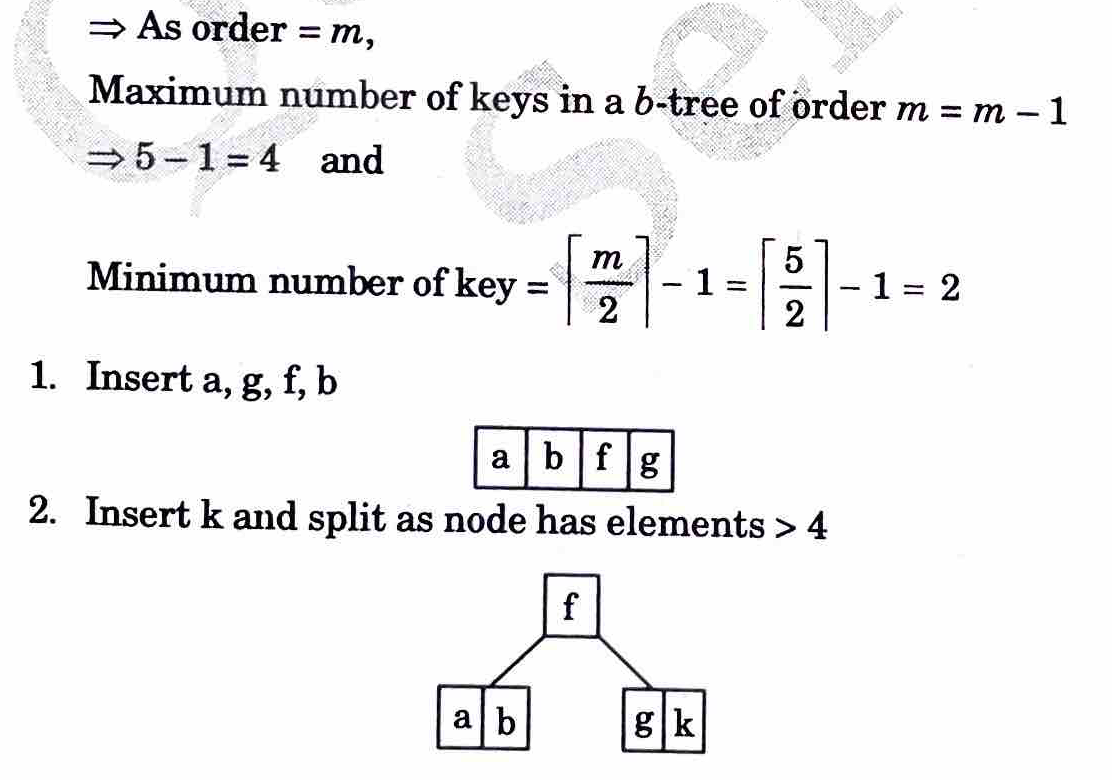
3. Insert d, h, m

4. Insert j and split
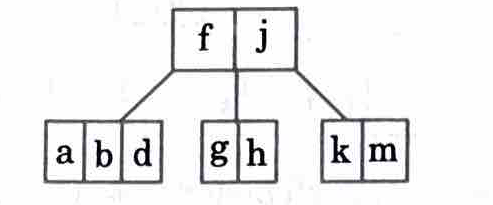
5. Insert e, s, i, r
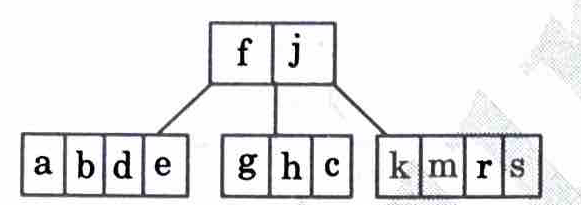
6. Insert x and split
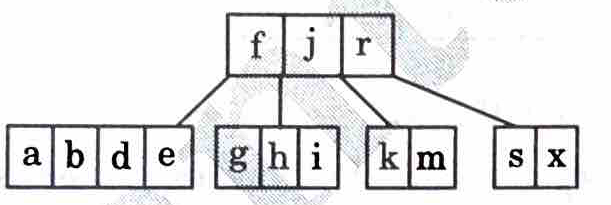
7. Insert c and split

8. Insert l, n, t, u
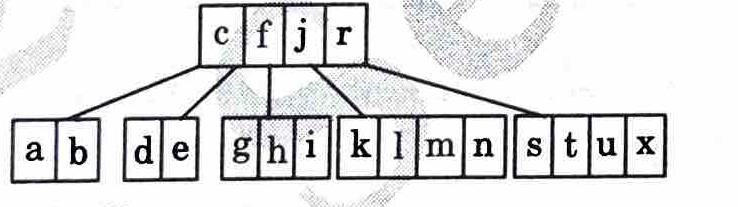
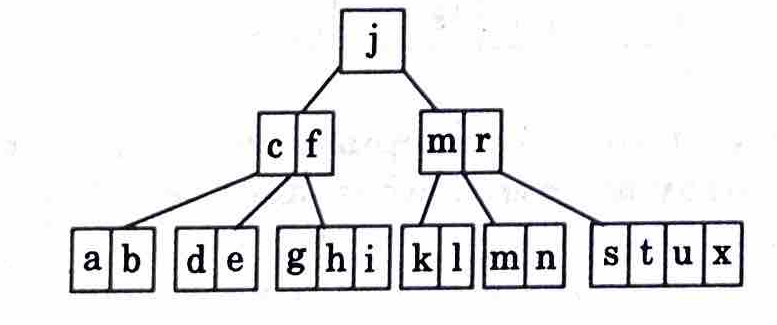
9. Insert p and split
M goes up and as root has now elements > 5 it is also split.
iii.
1. Delete j (Case 2 a) : j will borrow from its left subtree rooted at its left child.

2. Delete t (Case 1) : As all nodes upto the leaf node containing t has 2 keys, therefore, delete t.
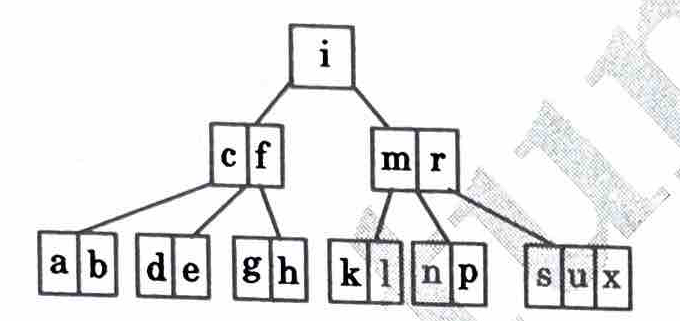
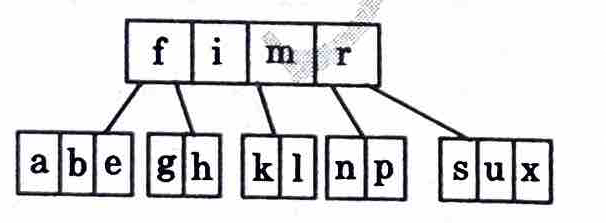
3. Deleted d (Case 3b) : As both the neighbours of nodes containing de have min keys, we cannot borrow from them, so we will bring their root key and merge it with its left neighbour and then delete d.

Now f has less than 2 keys, so we will bring root node down and merge it with its sibling.
b. i. Design a method for keeping two stack within a single linear array so that neither stack overflow until all the memory is used.
ii. Write a C program to reverse a string using stack.
Ans. i.
#include
#define MAX 50
int mainarray[MAX];
int top1 =-1,top2=MAX;
void push1(int elm)
{
if((top2-top1)==1)
{
clrscr();
printf(“\n Array has been Filled !!!”);
return;
}
mainarray[++top1] = elm
}
void push2(int elm)
{
if((top2-top1)==1)
{
clrscr();
printf(“\n Array has been Filled !!!”);
return;
}
mainarray[–op2] = elm;
}
int pop1()
{
int temp;
if(top1<0)
{
clrscr();
printf(“\n This Stack Is Empty!!!”);
return-1;
}
temp = mainarray[top1];
top1- -;
return temp;
}
int pop2()
{
int temp;
if(top2> MAX-1)
{
clrscr();
printf(“\n This Stack Is Empty !!!”);
return -1;
}
temp = mainarray[top2]
top2++;
return temp;
}
ii.
#include<stdio.h>
#include<conio.h>
#include<string.h>
#define MAX 20
int top=1
char stack [MAX];
char pop();
push(char),
main()
{
clrscr();
char str (20];
int i;
printf(“Enter the string: “);
gets(str);
for(i = 0; i < strlen(str); i++)
push (str [i]);
for(i = 0; i < strlen(str); i++)
str[i] = pop();
printf(“Reversed string is: “);
puts(str);
getch();
}
push (char item)
{
if(top == MAX – 1)
printf(“Stack overflow \n”);
else
stack[++top] = item;
}
char pop()
{
if(top ==-1)
printf(“Stack underflow \n”);
else
return stack [top- -];
}
Ans.

Cracking AKTU B.Tech: Quantum Data Structures – Last Year’s Short Questions Paper
| Important Question | Question Links |
|---|---|
| Data Structure – Unit-1 | UNIT-1 |
| Data Structure – Unit-2 | UNIT-2 |
| Data Structure – Unit-3 | UNIT-3 |
| Data Structure – Unit-4 | UNIT-4 |
| Data Structure – Unit-5 | Unit-5 |
| Important Short Questions- Data Structure | Short Question List |
| Last Year’s Question Paper | Exam 2021-22 |
| Quantum -Data structure | Quantum |
AKTU Important Links | Btech Syllabus
| Link Name | Links |
|---|---|
| Btech AKTU Circulars | Links |
| Btech AKTU Syllabus | Links |
| Btech AKTU Student Dashboard | Student Dashboard |
| AKTU RESULT (One VIew) | Student Result |
Important Links-Btech (AKTU)| Data Structures Syllabus
| Label | Links |
|---|---|
| Btech Information | Info Link |
| Btech CSE | CSE-LINK |
| Quantum-Page | Link |
| Data Structure Syllabus | Syllabus-DS |
2 thoughts on “AKTU B.Tech Data Structures: Latest Question Paper (2021-2022) for Exam Preparation”