
With our AKTU question and answer about Compiler Design, go out on a coding adventure. Young brains are introduced to the wonders of programming language translation and optimisation through notes written for students.
Dudes 🤔.. You want more useful details regarding this subject. Please keep in mind this as well. Important Questions For Compiler Design: *Quantum *B.tech-Syllabus *Circulars *B.tech AKTU RESULT * Btech 3rd Year
Section A: Short Notes of Compiler Design
a. What is the difference between parse tree and abstract syntax tree ?
Ans.
| S. No. | Parse tree | Abstract syntax tree |
| 1. | An ordered, rooted tree that, in some context-free grammar, depicts the syntactic structure of a string. | The abstract syntactic structure of source code written in a programming language is represented as a tree. |
| 2. | It contains records of the rules (tokens) to match input texts. | It contains records of the syntax of programming language. |
b. Explain the problems associated with top-down Parser.
Ans. Problems associated with top-down parsing are:
- 1. Backtracking
- 2. Left recursion
- 3. Left factoring
- 4. Ambiguity
c. What are the various errors that may appear in compilation process?
Ans. Types of errors that may appear in compilation process are:
- a. Lexical phase error
- b. Syntactic phase error
- c. Semantic phase error
d. What are the two types of attributes that are associated with a grammar symbol?
Ans. Two types of attributes that are associated with a grammar symbol are:
- a. Synthesized attributes
- b. Inherited attributes
e. Define the terms Language Translator and compiler.
Ans. Language translator: A programme called a language translator is used to convert instructions written in source code from high-level language or assembly language into machine language.
Compiler: When translating from a high-level programming language to a low-level programming language, a compiler is employed.
f. What is hashing? Explain.
Ans. Hashing is the process of transforming any given key or a string of characters into another value.
g. What is do you mean by left factoring the grammars ? Explain.
Ans. A grammar G is said to be left factored if any production of it is in form of:
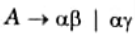
h. Define left recursion. Is the following grammar left recursive ?
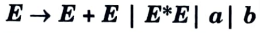
Ans. Left recursion: A grammar G(V, T, P, S) is said to be left recursive if it has a production in the form of:
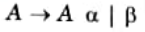
Numerical:
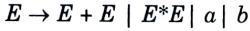
if we compare above grammar with
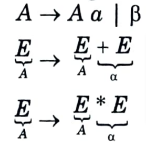
Yes, the given grammar is left recursive.
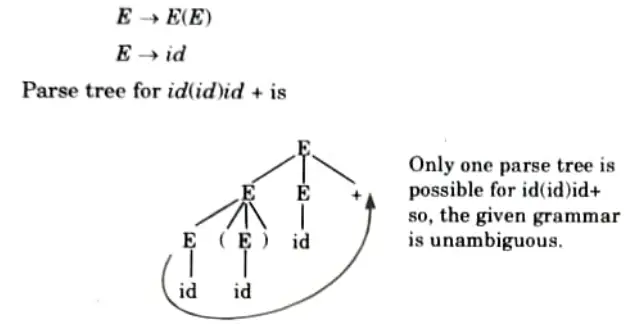
i. What is an ambiguous grammar ? Give example.
Ans. Ambiguous grammar: A context free grammar G is ambiguous is at if there least one string in L(G) having two or more distinct derivation tree.
Proof: Let production rule is given as:
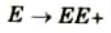
j. List down the conflicts during shift-reduce parsing.
Ans. Shift-reduce conflict:
- a. The most frequent kind of conflict in grammars is the shift-reduce conflict.
- b. This conflict arises because a production rule in the grammar is simultaneously decreased and shifted for the specific token.
- c. Recursive grammar definitions frequently lead to this issue since the system is unable to distinguish between when one rule is finished and when another is just getting started.
Section B: Important Notes of Compiler Design
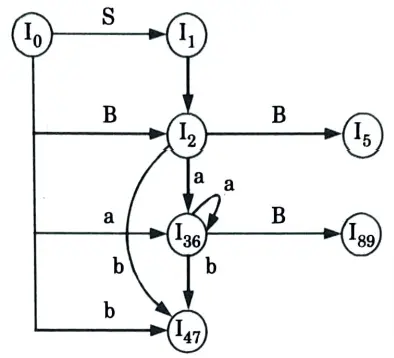
a. Construct the LALR parsing table for the given grammar
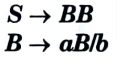
Ans. The given grammar is:
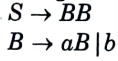
The augmented grammar will be:
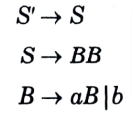
The LR (1) items will be:
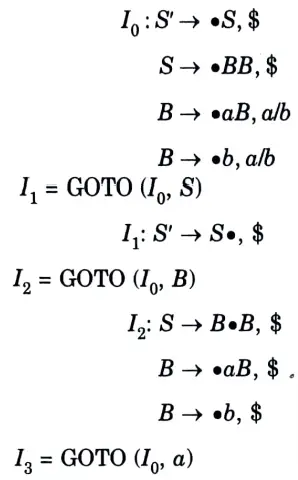
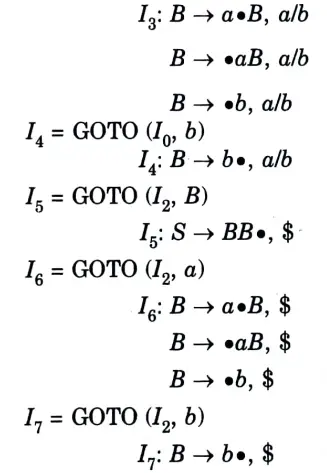
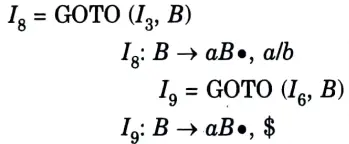
Table. 1
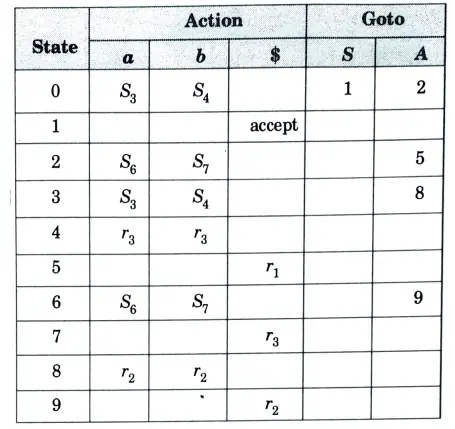
Since table does not contain any conflict. So it is LR(1).
The goto table will be for LALR I3 and I6 will be unioned, I4 and I7 will be unioned, and I8 and I9 will be unioned.
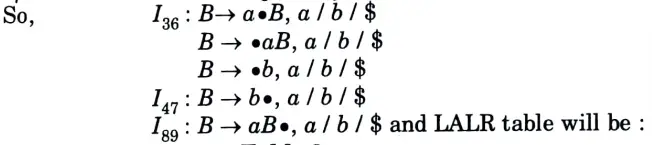
Table. 2
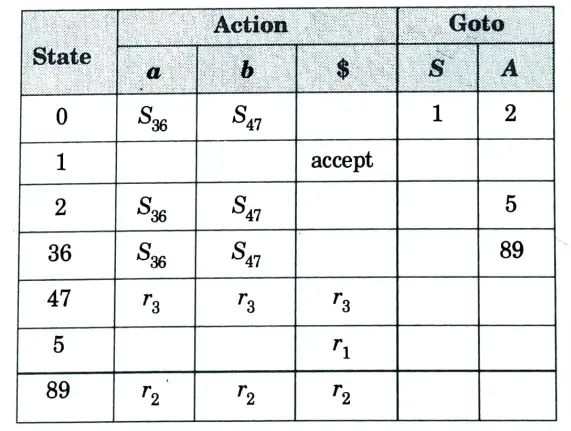
Since, LALR table does not contain any conflict. So, it is also LALR(1).
DFA:
b. What is an activation record ? Explain how it is related with runtime -storage organization ?
Ans. Activation record:
- 1. An activation record is used to organize the data required for a particular procedure run.
- 2. When a procedure is called, an activation record is pushed onto the stack, and it is popped when control is transferred back to the calling function.
Format of activation records in stack allocation:

Sub-division of run-time memory into codes and data areas is shown in Fig.
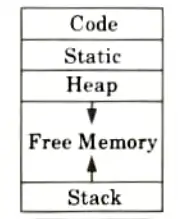
1. Code: It stores the executable target code which is of fixed size and do not change during compilation.
2. Static allocation:
- a. The static allocation is for all the data objects at compile time.
- b. The size of the data objects is known at compile time.
- c. This allocation of data objects is done via static allocation, and the names of these objects are only bound to storage at compile time.
- d. For static allocation, the compiler can estimate how much storage each data item needs. A compiler can easily locate the location of these data in the activation record as a result.
- e. The locations at which the target code can locate the data on which it works can be filled in by the compiler at the time of compilation.
3. Heap allocation: There are two methods used for heap management:
- a. Garbage collection method:
- i. An object is considered to be garbaged when all access paths to it are eliminated but the data object remains.
- ii. One method for reusing that object space is garbage collection.
- iii. Any components with the trash collection bit set to “on” are garbaged during garbage collection and returned to the free space list.
- b. Reference counter:
- i. Reference counters make an effort to reclaim each heap storage item as soon as it becomes inaccessible.
- ii. Each memory cell on the heap is connected to a reference counter that keeps track of the values that point to it.
- iii. The count is raised whenever a new value points to the cell and lowered whenever a value stops doing so.
4. Stack allocation:
- a. Activation record data structures are stored using stack allocation.
- b. As activations start and terminate, the activation records are pushed and popped, respectively.
- c. The record for each call in the activation procedure contains storage for the locals in that call. Locals are therefore guaranteed access to new storage in each activation because each call causes a new activation record to be pushed onto the stack.
- d. When the activation is finished, these local settings are removed.
c. Write the quadruple, triple, indirect triple for the following expression (s + y)*(y + 2) + (x + y + z)
Ans. The three address code for given expression:
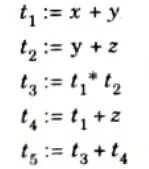
i. The quadruple representation:

ii. The triple representation:

iii. The indirect triple representation:

d. Discuss the following terms:
i. Basic block
ii. Next use information
iii. Flow graph
Ans. i. Basic block:
- a. Abasic block is a sequence of consecutive instructions with exactly one entry point and one exit point.
- b. The exit points may be more than one if we consider branch instructions.
ii. Next use information:
- a. Next-use information is needed for dead-code elimination and register allocation.
- b. Next-use is computed by a backward scan of a basic block.
- c. The next-use information will indicate the statement number at which a particular variable that is defined in the current position will be reused.
iii. Flow graph:
- 1. A flow graph is a directed graph in which the flow control information is added to the basie blocks.
- 2. The nodes to the flow graph are represented by basic blocks.
- 3. The block whose leader is the first statement is called initial blocks.
- 4. There is a directed edge from block Bi-1 to block Bi if Bi immediately follows Bi-1 in the given sequence. We can say that Bi-1 is a predecessor of Bi.
e. Construct predictive parse table for the following grammar.
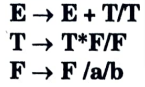
Ans.
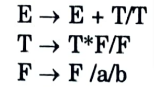
First we remove left recursion
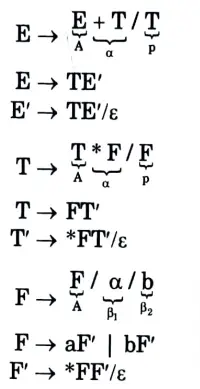
After removing left recursion, we get
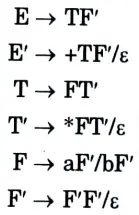

Predictive parsing table:
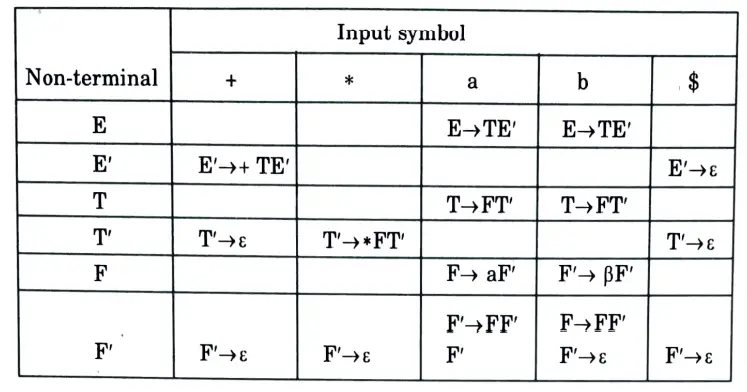
Section 3: Stack Allocation and Heap Allocation
a. Construct the SLR parse table for the following Grammar
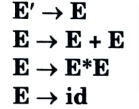
Ans. The augmented grammar is:
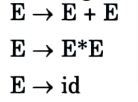
The canonical collection of sets o LR(0) items for grammar are as follows:
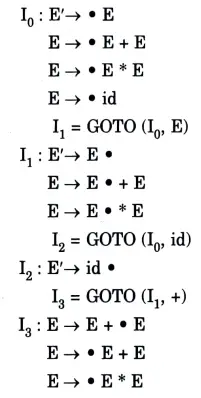
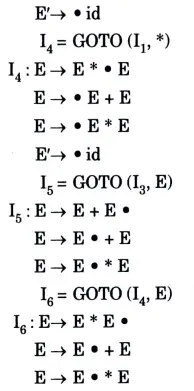
Let us numbered the production rules is the grammar as

SLR Parsing table:

DFA for set of items:
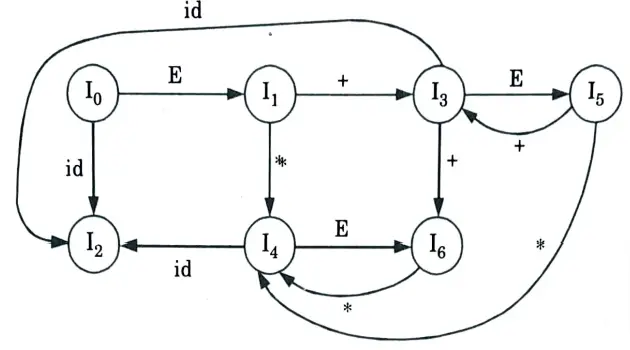
b. Differentiate between stack allocation and heap allocation.
Ans.
| S. No. | Static allocation | Heap allocation |
| 1. | Static allocation allocates memory on the basis of size of data objects. | Heap allocation makes use of heap for managing the allocation of memory at run time. |
| 2. | In static allocation, there is no possibility of creation of dynamic data structures and objects. | In heap allocation, dynamic data structures and objects are created. |
| 3. | In static allocation, the names of the data objects are fixed with storage for addressing. | Heap allocation allocates contiguous block of memory to data objects. |
| 4. | Static allocation is simple, but not efficient memory management technique. | Heap allocation does memory management in efficient way. |
| 5. | Static allocation strategy is faster in accessing data as compared to heap allocation. | Heap allocation is slow in accessing as there is chance of creation of holes in reusing the free space. |
| 6. | It is easy to implement. | It is comparatively expensive to implement. |
Section 4: Peephole Optimization
a. Write syntax directed definition for a given assignment statement:

Ans. The syntax directed definition of given grammar is:
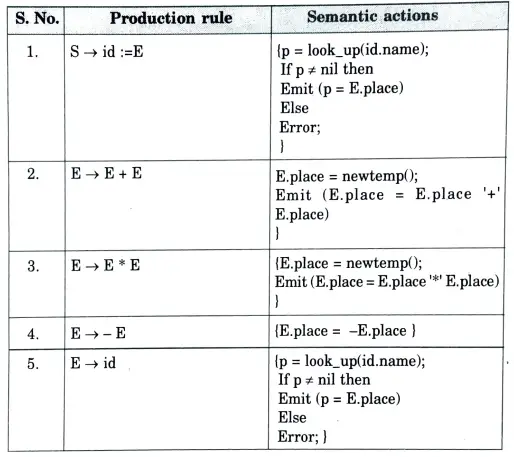
b. What are the advantages of DAG ? Explain the peephole optimization.
Ans. Advantages of DAG:
- 1. Using the DAG technique, we automatically identify frequent sub-expressions.
- 2. It is possible to identify which identifiers’ values are utilized in the block.
- 3. It is possible to identify which statements compute values that may be applied outside of the block.
Peephole optimization:
- 1. A specific kind of code optimization called peephole optimization is carried out on a small section of the code. It is applied to a piece of code’s extremely limited set of instructions.
- 2. It primarily relies on the principle of replacement, in which a section of code is changed for a quicker and shorter version without affecting the output.
- 3. The machine-dependent optimization is called Peephole.
Section 5: Lexical Phase Error and Syntactic Error
a. What do you understand by lexical phase error and syntactic error ? Also suggest methods for recovery of errors.
Ans. Lexical and syntactic error:
- a. A lexical phase error is a character sequence that does not match the pattern of a token, meaning that the compiler might not produce a valid token from the source programme when scanning it.
- b. Reasons due to which errors are found in lexical phase are:
- i. The addition of an extraneous character.
- ii. The removal of character that should be presented.
- iii The replacement of a character with an incorrect character.
- iv. The transposition of two characters.
For example:
- i. In Fortran, an identifier with more than 7 characters long is a lexical error.
- ii. In Pascal program, the character -, & and @ if occurred is a lexical error.
1. Panic mode recovery:
- a. The majority of parser techniques employ this approach because it is the simplest to implement.
- b. If a parser encounters an error, it discards each input symbol individually until one of the predetermined set of synchronizing tokens is discovered.
- c. Frequently, panic mode correction misses a sizable portion of the input without examining it for more faults. It ensures that there won’t be an endless loop.
For example:
Let consider a piece of code:
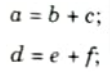
By using panic mode it skips a = b + c without checking the error in the code.
2. Phrase-level recovery:
- a. When a parser finds an error, it may locally repair the remaining input.
- b. It might substitute a string that enables the parser to proceed for a prefix of the remaining input.
- c. A typical local modification might remove an unnecessary semicolon, insert a needed semicolon, and replace a comma with a semicolon.
For example:
Let consider a piece of code
while (x > 0) y = a + b;
In this code local correction is done by phrase-level recovery by adding ‘do’ and parsing is continued.
3. Error production: If error production is used by the parser, we can generate appropriate error message and parsing is continued.
For example:
Let consider a grammar
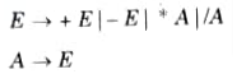
When error production encounters *A, it sends an error message to the user asking to use ‘*’ as unary or not.
4. Global correction:
- a. Global correction is a theoretical concept.
- b. This method increases time and space requirement during parsing.
b. Discuss how induction variables can be detected and eliminated from the given intermediate code
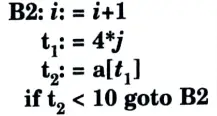
Ans. In the given question, there is no induction variable.
If we replace j with i. then the block B2 becomes
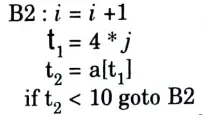
In the above block B2 value of i is incremented by every time in the loop and value of t1 is incremented 4 times the value of i.
So, in the given block i and t1 are two induction variables.
In this case, if we want to remove the induction variables we use reduction is strength technique.
In this technique, we remove same line of code out of the block or modify the computation code in the block.
Modification:
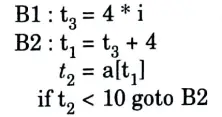
Section 6: Static Scope and Dynamic Scope
a. Test whether the grammar is LL (1) or not, and construct parsing table for it.
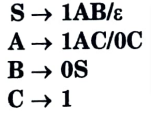
Ans. Given grammar:

Parsing table:

Since, no column has more than one value. So the given grammar is LL(1) grammar.
b. Distinguish between static scope and dynamic scope. Briefly explain access to non local names in static scope.
Ans. Difference:
| S. No. | Lexical scope | Dynamic scope |
| 1. | The binding of name occurrences to declarations is done statistically at compile time. | At runtime, name occurrences are dynamically bound to declarations. |
| 2. | The structure of the program defines the binding of variables. | The binding of variables is defined by the flow of control at the run time. |
| 3. | The environment in which a process is defined determines the value of any free variables used within that procedure. | A free variable gets its value from where the procedure is called. |
Access to non-local names in static scope:
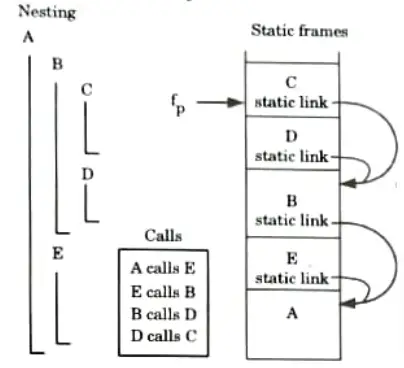
- 1. The method used to implement non-local names (variable) access in static scope is called static chain.
- 2. An activation record instance in the stack that is connected by a static chain consists of static links.
- 3. An activation record instance for subprogram A points to one of the activation record instances of A’s static parent via the static ink, or static scope pointer.
- 4. When an object declared in a static parent at the surrounding scope nested at level k is referenced by a subroutine at the nesting level, J-k static links generate a static chain that must be navigated to reach the frame containing the object.
- 5. In order to reach non-local names, the compiler generates code that performs these frame traversals.
For example: Subroutine A is at nesting level 1 and Cat nesting level 3. When C accesses an object of A, 2 static links are traversed to get to A’s frame that contains that object
Section 7: Code Generator and Code Loop Optimization
a. What are the various issues in design of code generator and code loop optimization ?
Ans. Various issues of code generator:
- 1. Input to the code generator:
- a. The source program’s intermediate representation created by the front end, combined with data from the symbol table, are the inputs to the code generator.
- b. Graphical representations and three address representations are both included in IR.
- 2. The target program:
- a. The complexity of building a decent code generator that creates high quality machine code is significantly influenced by the target machine’s instruction set architecture.
- b. The most popular target machine architectures are stack based, CISC (Complex Instruction Set Computer), and RISC (Reduced Instruction Set Computer).
- 3. Instruction selection:
- a. The target machine must be able to execute the code sequence that the code generator creates from the IR program.
- b. If the IR is high level, the code generator may use code templates to convert each IR statement into a series of machine instructions.
- 4. Register allocation:
- a. A key problem in code generation is deciding what values to hold in which registers on the target machine do not have enough space to hold all values.
- b. Values that are not held in registers need to reside in memory. Instructions involving register operands are invariably shorter and faster than those involving operands in memory, so efficient utilization of registers is particularly important.
- c. The use of registers is often subdivided into two subproblems:
- i. Register allocation, during which we select the set of variables that will reside in registers at each point in the program.
- ii. Register assignment, during which we pick the specific register that a variable will reside in.
- 5. Evaluation order:
- a. The order in which computations are performed can affect the efficiency of the target code.
- b. Some computation orders require fewer registers to hold intermediate results than others.
Various issues of code loop optimization:
1. Function preserving transformation: The function preserving transformations are basically divided into following types:
a. Common sub-expression elimination:
- i. A common sub-expression is just an expression that has previously been computed and is utilized repeatedly throughout the programme.
- ii. We stop computing the same expression repeatedly if the outcome of the expression is unchanged.
For example:
Before common sub-expression elimination:
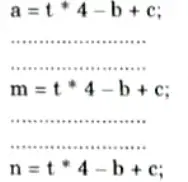
After common sub-expression elimination:
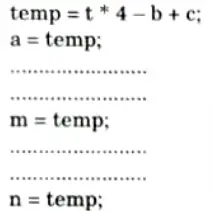
- iii. In given example, the equation a = t * 4 – b + c is occurred most of the times. So it is eliminated by storing the equation into temp variable.
b. Dead code elimination:
- i. Dead code means the code which can be emitted from program and still there will be no change in result.
- ii. A variable is live only when it is used in the program again and again. Otherwise, it is declared as dead, because we cannot use that variable in the program so it is useless.
- iii. The dead code occurred during the program is not introduced intentionally by the programmer.
For example:

- iv. If false becomes zero, is guaranteed then code in ‘IF’ statement will never be executed. So, there is no need to generate or Write code tor this statement because it is dead code.
c. Copy propagation:
- i. Copy propagation is the concept where we can copy the result of common sub-expression and use it in the program.
- ii. In this technique the value of variable is replaced and computation of an expression is done at the compilation time.
For example:
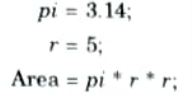
Here at the compilation time the value of pi is replaced by 3.14 and r by 5.
d. Constant folding (compile time evaluation):
- i. Constant folding is defined as replacement of the value of one constant in an expression by equivalent constant value at the compile time.
- ii. In constant folding all operands in an operation are constant. Original evaluation can also be replaced by result which is also constant.
For example: a = 3.14157/2 can be replaced by a = 1.570785 thereby eliminating a division operation.
2. Algebraic simplification:
a. Peephole optimization is an effective technique for algebraic simplification.
b. The statements such as
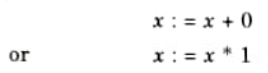
can be eliminated by peephole optimization.
b. Generate the three address code for the following code fragment.
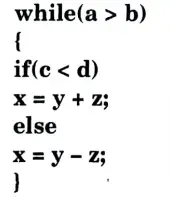
Ans. Three address code for the given code:

6 thoughts on “Compiler Design: Solved Question Paper with Quantum Notes”